一. 介绍
由于每个PXC集群有3个节点,故需要使用mycat进行读写分离,分摊单个节点的读写压力。
同时由于有两套PXC集群,故需要针对不同表采用不同分片算法进行数据路由。
因为mycat不支持跨分片表连接,还需要配置父子表等,让需要表连接操作的数据路由到同一个分片中。
二. JDK安装与配置
-
安装JDK
#搜索JDK版本 yum search jdk #安装JDK1.8开发版 yum install java-1.8.0-openjdk-devel.x86_64 -
配置环境变量
#查看JDK安装路径 ls -lrt /etc/alternatives/java vi /etc/profile #在文件结尾加上JDK路径 JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64/ PATH=$JAVA_HOME/bin:$PATH export PATH JAVA_HOME source /etc/profile
三. 创建数据表
创建两套PXC集群,每套3台机器
-
在两组PXC集群中分别创建t_user数据表
CREATE TABLE t_user ( id INT(10) UNSIGNED NOT NULL, username VARCHAR(200) NOT NULL, password VARCHAR(200) NOT NULL, tel CHAR(11) NOT NULL, locked TINYINT(1) UNSIGNED NULL, PRIMARY KEY (ID) USING BTREE, INDEX `idx_username` (`username`) USING BTREE, UNIQUE INDEX `unq_username` (`username`) USING BTREE ) COMMENT 'pxc测试表';
四、MyCat安装与配置
-
下载MyCat
http://dl.mycat.io/1.6.5/Mycat-server-1.6.5-release-20180122220033-linux.tar.gz
-
上传MyCat压缩包到虚拟机
-
安装unzip程序包,解压缩MyCat
yum install unzip unzip MyCAT压缩包名称 -
开放防火墙8066和9066端口,关闭SELINUX
-
修改MyCat的bin目录中所有.sh文件的权限
chmod -R 777 ./*.sh -
MyCat启动与关闭
#cd MyCat的bin目录 ./startup_nowrap.sh #启动MyCat ps -aux #查看系统进程 kill -9 MyCat进程编号
mycat配置文件解析
| 文件 | 作用 | 修改内容 |
|---|---|---|
| rule.xml | 切分算法 | 修改mod-long分片数量为2 |
| server.xml | 虚拟MySQL | 修改用户名、密码和逻辑库 |
| scnema.Xml | 数据库连接、读写分离、负载均衡、数据表映射 | 定义连接、读写分离、负载均衡、数据表映射 |
-
修改server.xml文件,设置MyCat帐户和虚拟逻辑库
0 1 0 0 2 false 0 0 1 64k 1k 0 384m false Abc_123456 test -
修改schema.xml文件,设置数据库连接和虚拟数据表
此处有两个分片,则配置两个dataHost
重点配置介绍
1. balance 属性
负载均衡类型,目前的取值有 3 种:
- balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
- balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双 主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载 均衡。
- balance="2",所有读操作都随机的在 writeHost、readhost 上分发。防止写节点浪费
- balance="3",所有读请求随机的分发到 wiriterHost 对应的 readhost 执行,writerHost 不负担读压力, 注意 balance=3 只在 1.4 及其以后版本有,1.3 没有。
2. writeType 属性
负载均衡类型,目前的取值有 3 种:
- writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个 writeHost, 重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
- writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐。
3. switchType 属性
- -1 表示不自动切换。
- 1 默认值,自动切换。
- 2 基于 MySQL 主从同步的状态决定是否切换。
select user()
select user()
-
修改rule.xml文件,把mod-long的count值修改成2
2 -
放行端口
8066:数据服务
9066:管理端口
-
重启MyCat
$ ./startup_nowrap.sh关闭命令:
$ ps -aux | grep mycat $ kill $PID -
向t_user表写入数据,感受数据的切分
USE test; select * from t_user; #第一条记录被切分到第二个分片 INSERT INTO t_user(id,username,password,tel,locked) VALUES(1,"A",HEX(AES_ENCRYPT('123456','HelloWorld')),"12345678901",false); #第二条记录被切分到第一个分片 INSERT INTO t_user(id,username,password,tel,locked) VALUES(2,"B",HEX(AES_ENCRYPT('123456','HelloWorld')),"12345678912",false);
五、配置数据分片和父子表
1. 数据切分算法
| 切分算法 | 适用场合 | 备注 |
|---|---|---|
| 主键求模切分 | 数据增长速度慢,难于增加分片 | 有明确主键值 |
| 枚举值切分 | 归类存储数据,适合大多数业务 | |
| 主键范围切分 | 数据快速增长,容易增加分片 | 有明确主键值 |
| 日期切分 | 数据快速增长,容易增加分片 |
(1)主键求模切分
-
求模切分适合用在初始数据很大,但是数据增长不快的场景
-
求模切分的弊病在于扩展新分片难度大,迁移的数据太多
-
建议扩张后的分片数是原有分片的2n倍

(2)枚举值切分
- 按照某个字段的值(数字)来切分数据
2. 数据分片
-
在conf目录下创建
customer-hash-int文件,内容如下:101=0 102=0 103=0 104=1 105=1 106=1 -
在rule.xml文件中加入自定义
和 customer-hash-int.txt sharding_id customer-hash-int -
修改schema.xml文件,配置数据分片算法
-
重载mycat配置
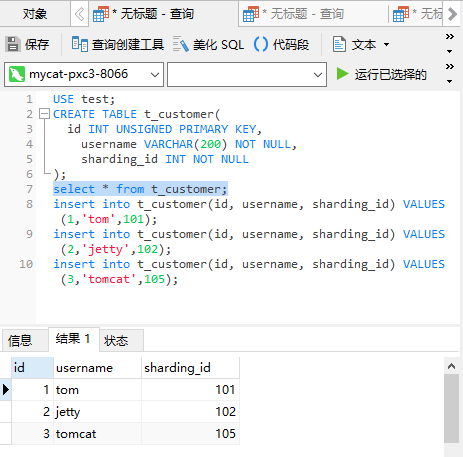
使用navicat打开命令行界面,执行语句
reload @@config_all;USE test; CREATE TABLE t_customer( id INT UNSIGNED PRIMARY KEY, username VARCHAR(200) NOT NULL, sharding_id INT NOT NULL ); select * from t_customer; insert into t_customer(id, username, sharding_id) VALUES (1,'tom',101); insert into t_customer(id, username, sharding_id) VALUES (2,'jetty',102); insert into t_customer(id, username, sharding_id) VALUES (3,'tomcat',105);第一个分片

第二个分片
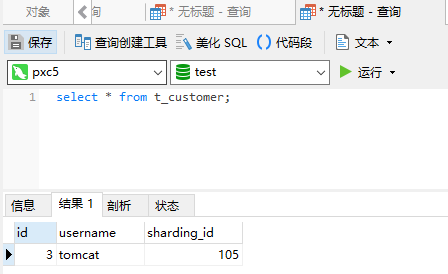
查询mycat数据
3. 父子表
出现原因:在 MyCat中是不允许跨分片做表连接查询的
解决原理:部分业务总会可以抽象出父子关系的表。这类表适用于 ER 分片表,子表的记录与 所关联的父表记录存放在同一个数据分片上,避免数据 Join 跨库操作
- 修改schema.xml文件,添加父子表定义。此处定义成父表t_customer允许分在不同分片,子表t_orders不允许跨分片。一个父表可以包含多个子表,子表也可嵌套多个子表。
-
重载mycat配置
使用navicat打开命令行界面,执行语句
reload @@config_all; -
在MyCat上执行如下SQL:
USE test; CREATE TABLE t_orders( id INT PRIMARY KEY, customer_id INT NOT NULL, datetime TIMESTAMP DEFAULT CURRENT_TIMESTAMP ); -
向t_customer表和t_orders表写入数据,查看字表数据跟随父表切分到同一个分片
-- 预期写入第一个分片
insert into t_orders(id, customer_id) VALUES (1,1);
insert into t_orders(id, customer_id) VALUES (2,1);
insert into t_orders(id, customer_id) VALUES (3,1);
-- 预期写入第二个分片
insert into t_orders(id, customer_id) VALUES (4,2);
insert into t_orders(id, customer_id) VALUES (5,3);
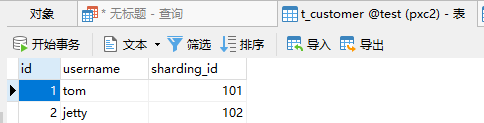
分片一t_customer查询结果
分片一t_orders查询结果
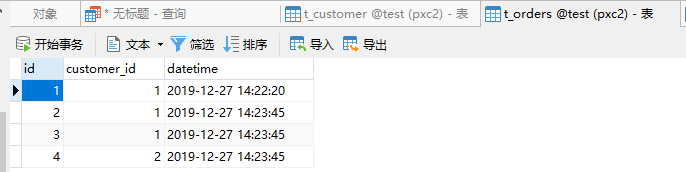
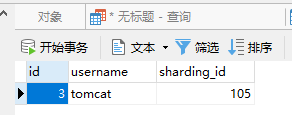
分片二t_customer查询结果
分片二t_orders查询结果
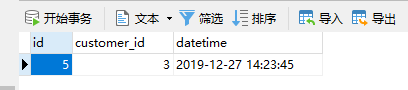
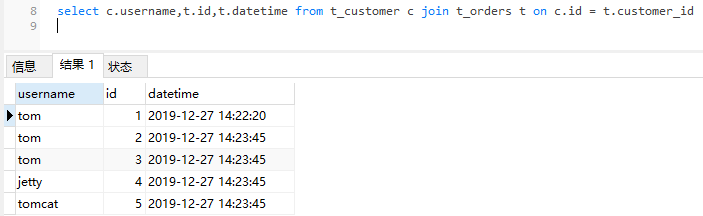
同一个客户订单和客户信息都存在相同分片中,结果符合预期
连接查询测试
select c.username,t.id,t.datetime from t_customer c join t_orders t on c.id = t.customer_id