一、介绍
1. InnoDB写入慢的原因
采用BTREE索引,IO占用高
2. TokuDB优点
- 高压缩比(1:12,是InnoDB的14倍),高写入性能(是InnoDB的10-20倍)
- 在线创建索引和字段
- 支持事物(写入性能是InnoDB的9-20倍)
- 支持主从同步
3. 归档规划
- 使用TokuDB引擎保存归档数据,拥有高速写入特性
- 使用双机热备方案搭建归档库,具备高可用性
- 使用pt-archiver执行数据归档,简便易行
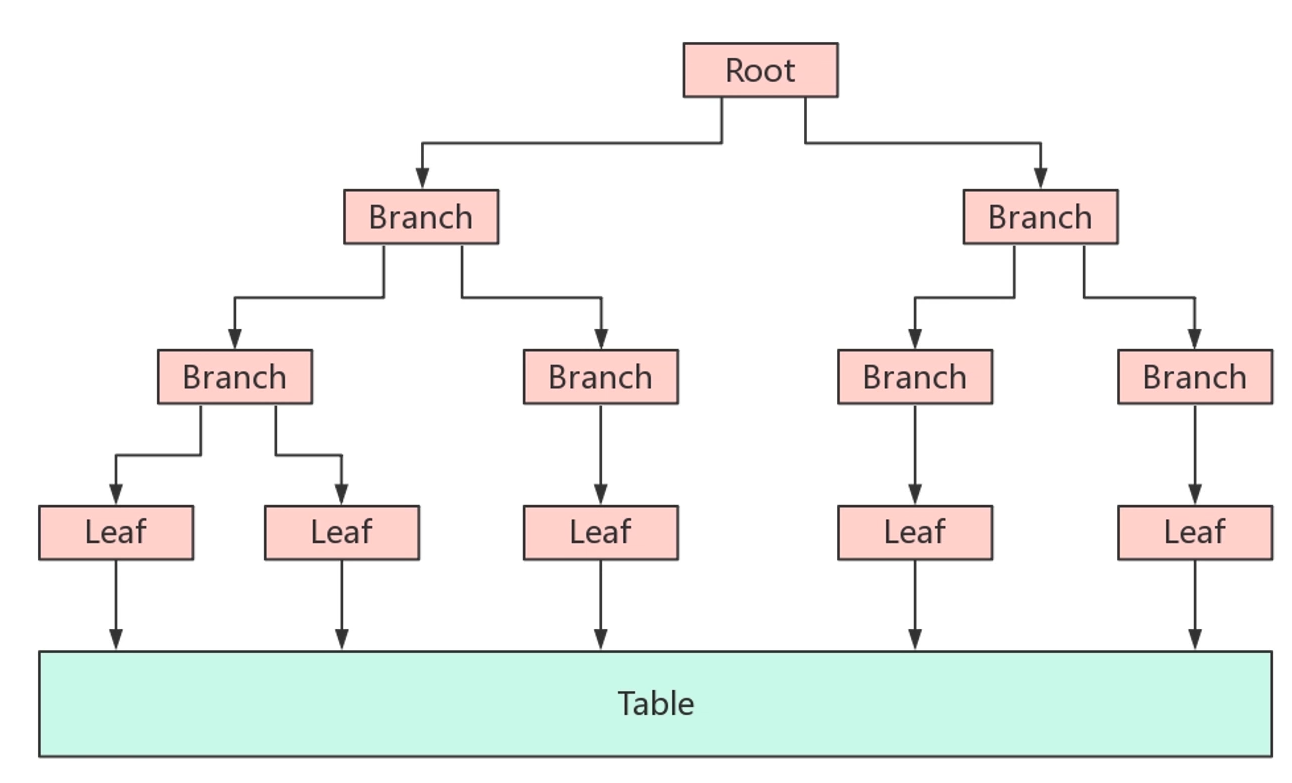
二、 安装TokuDB
-
安装jemlloc
yum install -y jemalloc -
编辑配置文件
vi /etc/my.cnf…… [mysqld_safe] malloc-lib=/usr/lib64/libjemalloc.so.1 …… -
重启MySQL
systemctl restart mysqld -
开启Linux大页内存,同时开启内存碎片整理
linux系统默认在系统启动时进行内存分配,后续将不再管理内存
echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defrag -
安装TokuDB
yum install -y Percona-Server-tokudb-57.x86_64 ps-admin --enable -uroot -p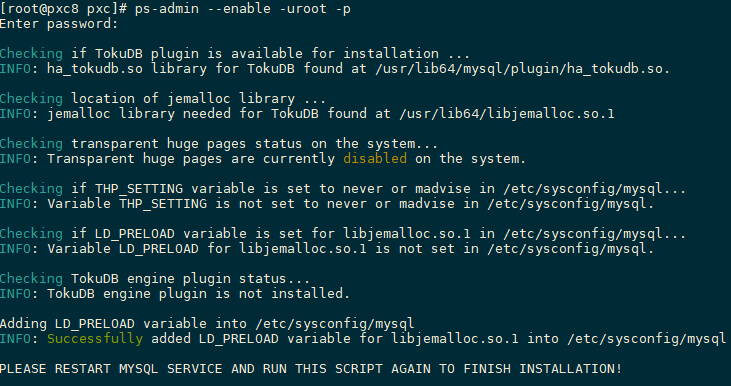
重启数据库再次执行安装
service mysqld restart ps-admin --enable -uroot -p提示引擎已经成功安装
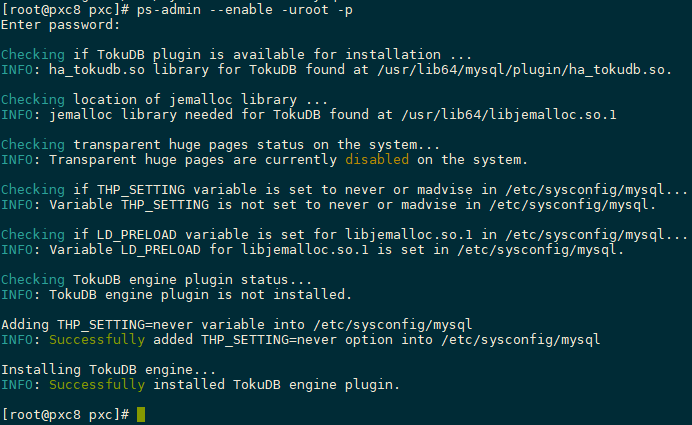
-
查看安装结果
show engines ;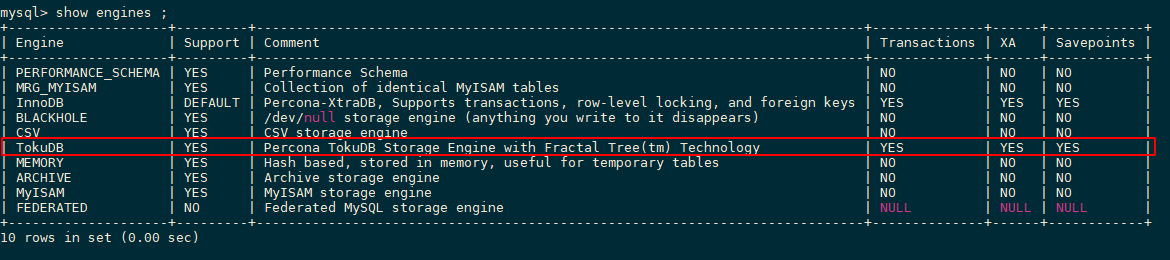
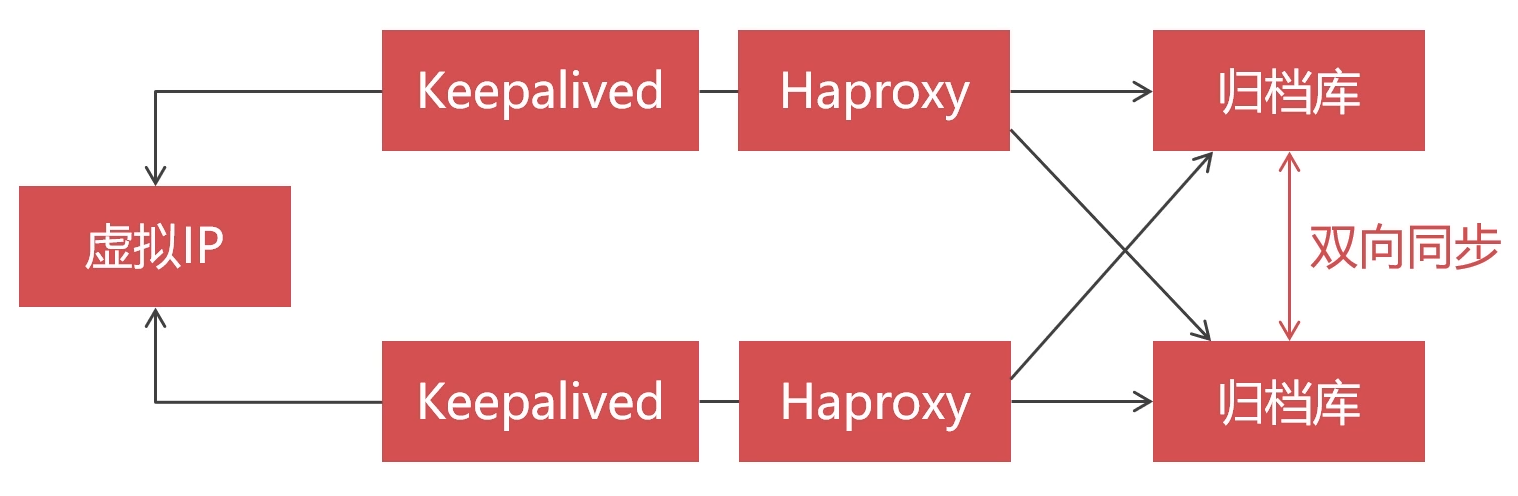
三、配置Replication集群
集群设计——双向同步Replication集群
原因:默认情况下Replication模式单向同步,若主库宕机,则向从库写入数据。若主库重新上线,则不会自动同步数据,导致数据不一致
架构图
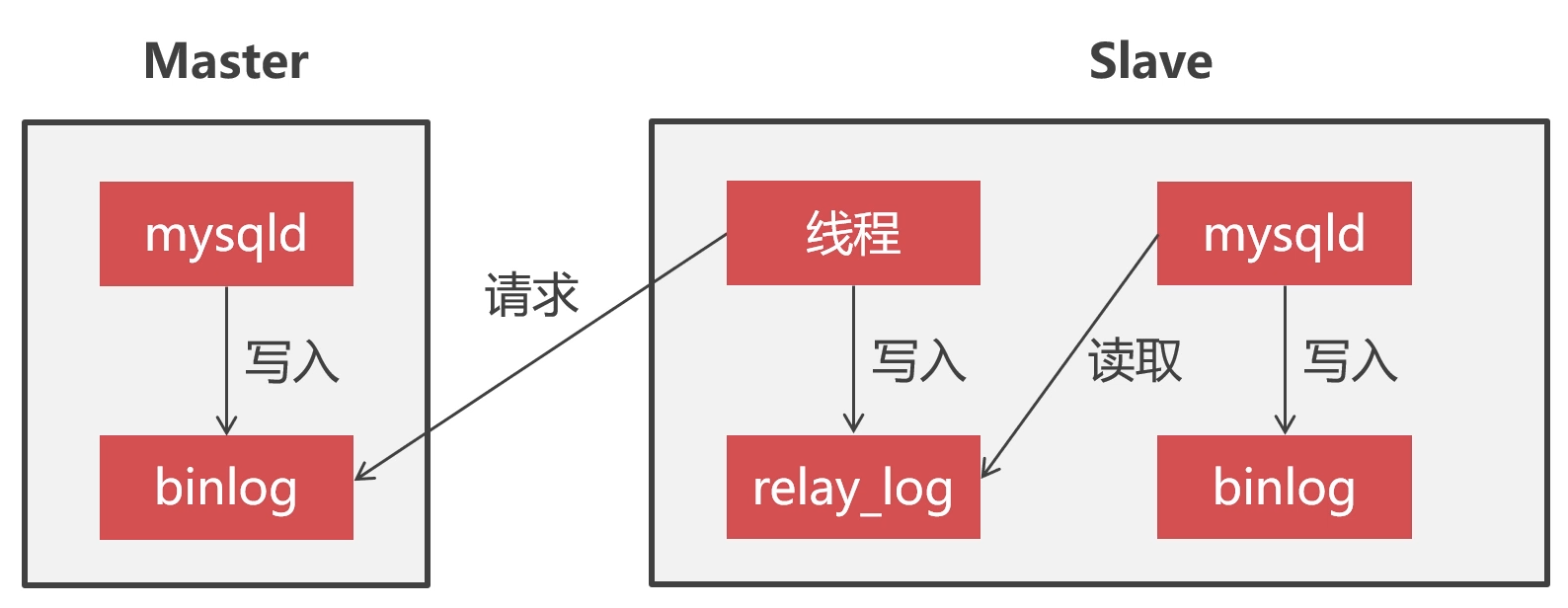
replication集群同步原理
配置互为主从的replication集群
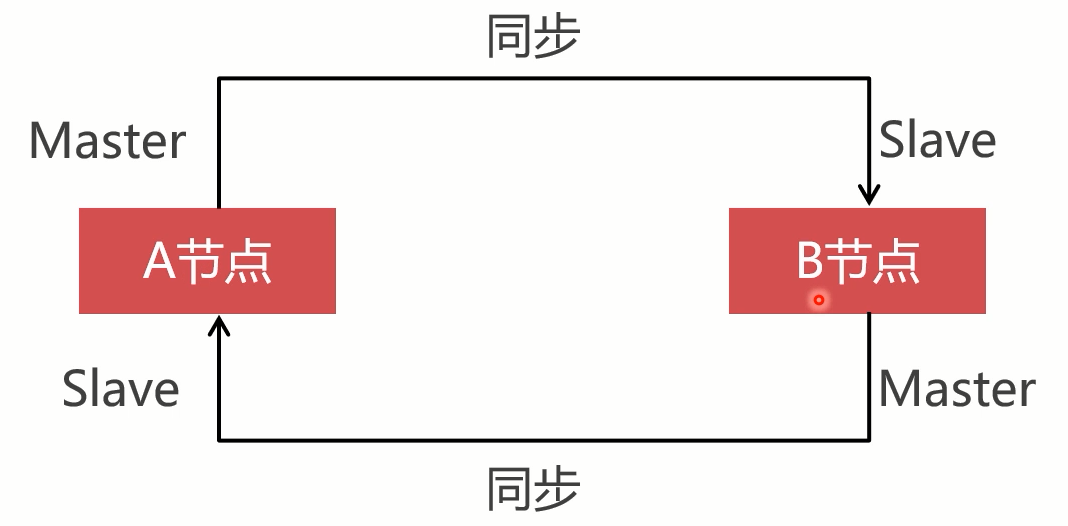
-
在两个TokuDB数据库上创建用户
CREATE USER 'tokubackup'@'%' IDENTIFIED BY 'Abc_123456' ;GRANT super, reload, replication slave ON *.* TO 'tokubackup'@'%' ;FLUSH PRIVILEGES ; -
修改两个TokuDB的配置文件
/etc/my.cnf,如下:[mysqld] server_id = 101 log_bin = mysql_bin relay_log = relay_bin ……[mysqld] server_id = 102 log_bin = mysql_bin relay_log = relay_bin -
重新启动两个TokuDB节点
service mysqld restart -
分别在两个TokuDB上执行下面4句SQL
当前数据库架构,首先让B节点向A节点同步数据
graph LR A节点-->B节点; subgraph Master A节点 end subgraph Slave B节点 end在B节点执行语句
#关闭同步服务 stop slave; #设置同步的Master节点 change master to master_host="pxc1",master_port=3306,master_user="backup", master_password="Abc_123456"; #启动同步服务 start slave; #查看同步状态 show slave status;执行结果

当如下两个字段为yes,则说明主从同步已经开启

在A节点启动主从同步
#关闭同步服务 stop slave; #设置同步的Master节点 change master to master_host="pxc8",master_port=3306,master_user="backup", master_password="Abc_123456"; #启动同步服务 start slave; #查看同步状态 show slave status;
执行结果

## 四、创建归档表
通常按年份定义归档表分表名称,选择任意一个节点执行即可,此处选择在PXC1节点上执行
```mysql
CREATE DATABASE test;
USE test;
CREATE TABLE t_purchase_20191230 (
id INT UNSIGNED PRIMARY KEY,
purchase_price DECIMAL(10,2) NOT NULL,
purchase_num INT UNSIGNED NOT NULL,
purchase_sum DECIMAL (10,2) NOT NULL,
purchase_buyer INT UNSIGNED NOT NULL,
purchase_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
company_id INT UNSIGNED NOT NULL,
goods_id INT UNSIGNED NOT NULL,
KEY idx_company_id(company_id),
KEY idx_goods_id(goods_id)
)engine=TokuDB;
在PXC8节点上也看到了新增的数据表
五、配置Haproxy+Keepalived双机热备
-
在两个节点上安装Haproxy,此处使用之前搭建的两个节点Haproxy
yum install -y haproxy -
修改配置文件
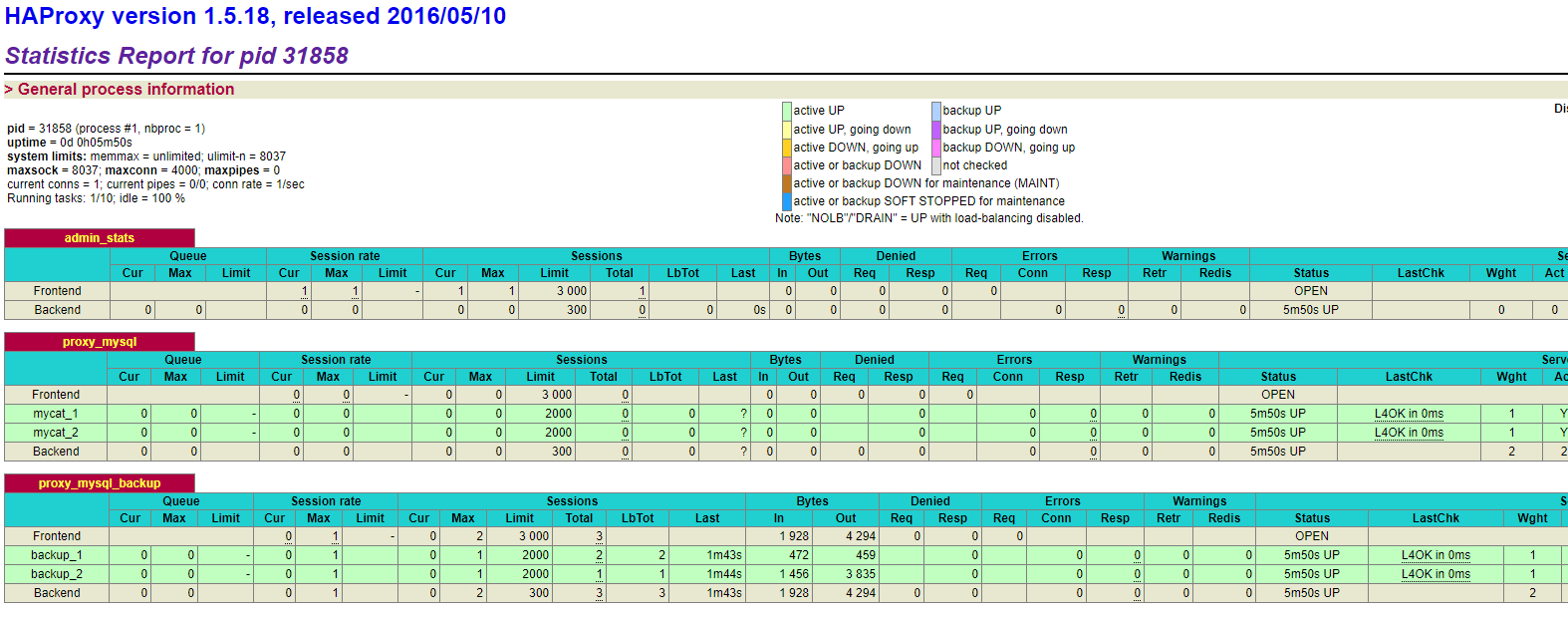
vi /etc/haproxy/haproxy.cfgglobal log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon stats socket /var/lib/haproxy/stats defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 listen admin_stats bind 0.0.0.0:4001 mode http stats uri /dbs stats realm Global\ statistics stats auth admin:Abc%6870 listen proxy_mysql bind 0.0.0.0:13306 mode tcp balance roundrobin option tcplog server mycat_1 192.168.1.33:8066 check port 8066 weight 1 maxconn 2000 server mycat_2 192.168.1.36:8066 check port 8066 weight 1 maxconn 2000 option tcpka # 新增配置 listen proxy_mysql_backup bind 0.0.0.0:13307 mode tcp balance roundrobin option tcplog #日志格式 server backup_1 pxc1:3306 check port 3306 maxconn 2000 server backup_2 pxc8:3306 check port 3306 maxconn 2000 option tcpka #使用keepalive检测死链 -
重启Haproxy
-
开启防火墙的VRRP协议
firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --protocol vrrp -j ACCEPTfirewall-cmd --reload查看配置结果
-
在两个节点上安装Keepalived,此处复用之前的Keepalived
六、准备归档数据
-
在两个PXC分片上创建进货表,默认是InnoDB引擎
CREATE TABLE t_purchase ( id INT UNSIGNED PRIMARY KEY, purchase_price DECIMAL(10,2) NOT NULL, purchase_num INT UNSIGNED NOT NULL, purchase_sum DECIMAL (10,2) NOT NULL, purchase_buyer INT UNSIGNED NOT NULL, purchase_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, company_id INT UNSIGNED NOT NULL, goods_id INT UNSIGNED NOT NULL, KEY idx_company_id(company_id), KEY idx_goods_id(goods_id) ) -
配置MyCat的schema.xml文件,并重启MyCat
使用Java程序导入10万条测试数据,由mycat路由到两个分片中
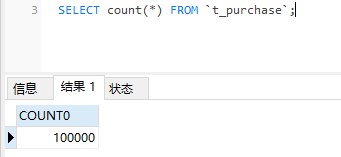
测试数据的时间为2019年11月21日
七、执行数据归档
pt-archiver用途:
-
导出线上数据,到线下数据作处理
-
清理过期数据,并把数据归档到本地归档表中,或者远端归档服务器
-
安装pt-archiver
yum install -y percona-toolkit -
查看版本
$ pt-archiver --version pt-archiver 3.1.0 -
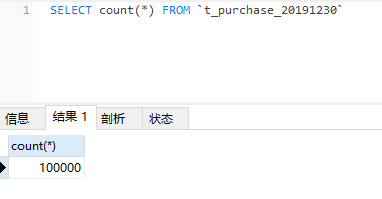
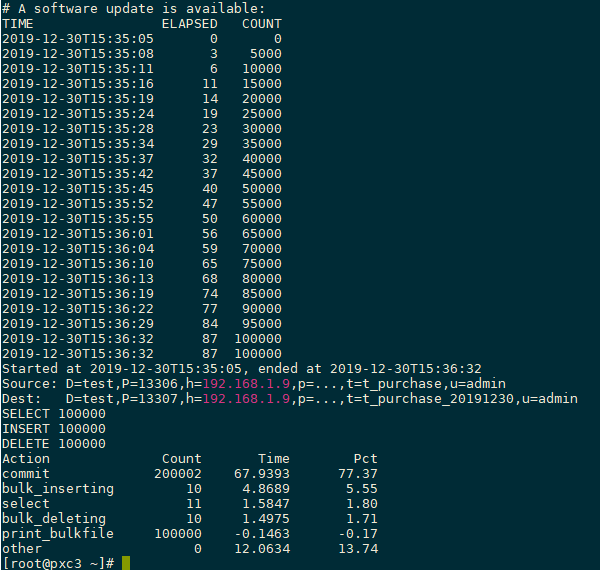
执行数据归档
--bulk-delete --bulk-insert表示对源库批量删除,对归档库批量导入,该归档过程包含事务,故不会导致数据丢失pt-archiver --source h=192.168.1.9,P=13306,u=admin,p='password',D=test,t=t_purchase --dest h=192.168.1.9,P=13307,u=admin,p='password',D=test,t=t_purchase_20191230 --no-check-charset --where 'purchase_date<"2019-11-30 00:00:00"' --progress 5000 --bulk-delete --bulk-insert --limit=10000 --statistics迁移结果
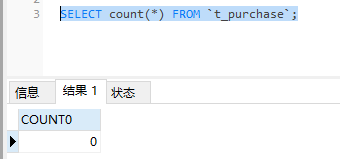
查询源库,记录已全部迁移
查询归档库