背景
在ChatGPT引爆大语言模型热潮下,国内清华大学开源了包含62亿参数的GLM-6B,由于使用的参数较少,因此能支持在消费级显卡上私有化部署体验。
硬件
CPU:12700
内存:32G
GPU:RTX 2060 SUPER 8G
实践-ChatGLM-6B官方版本
介绍
GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。
部署
采用秋叶一键部署包,使用8G显存版本
启动成功,访问web-ui
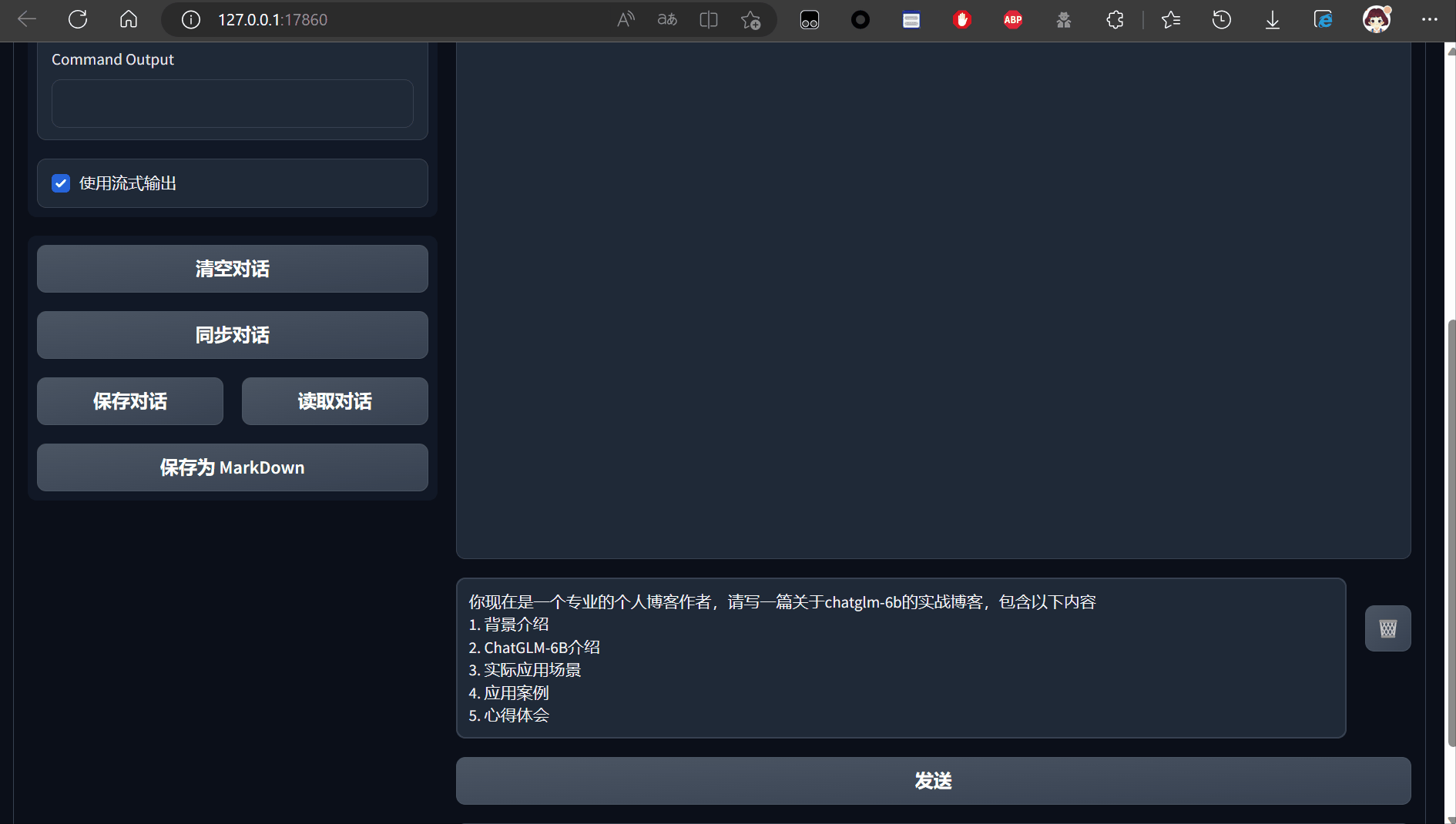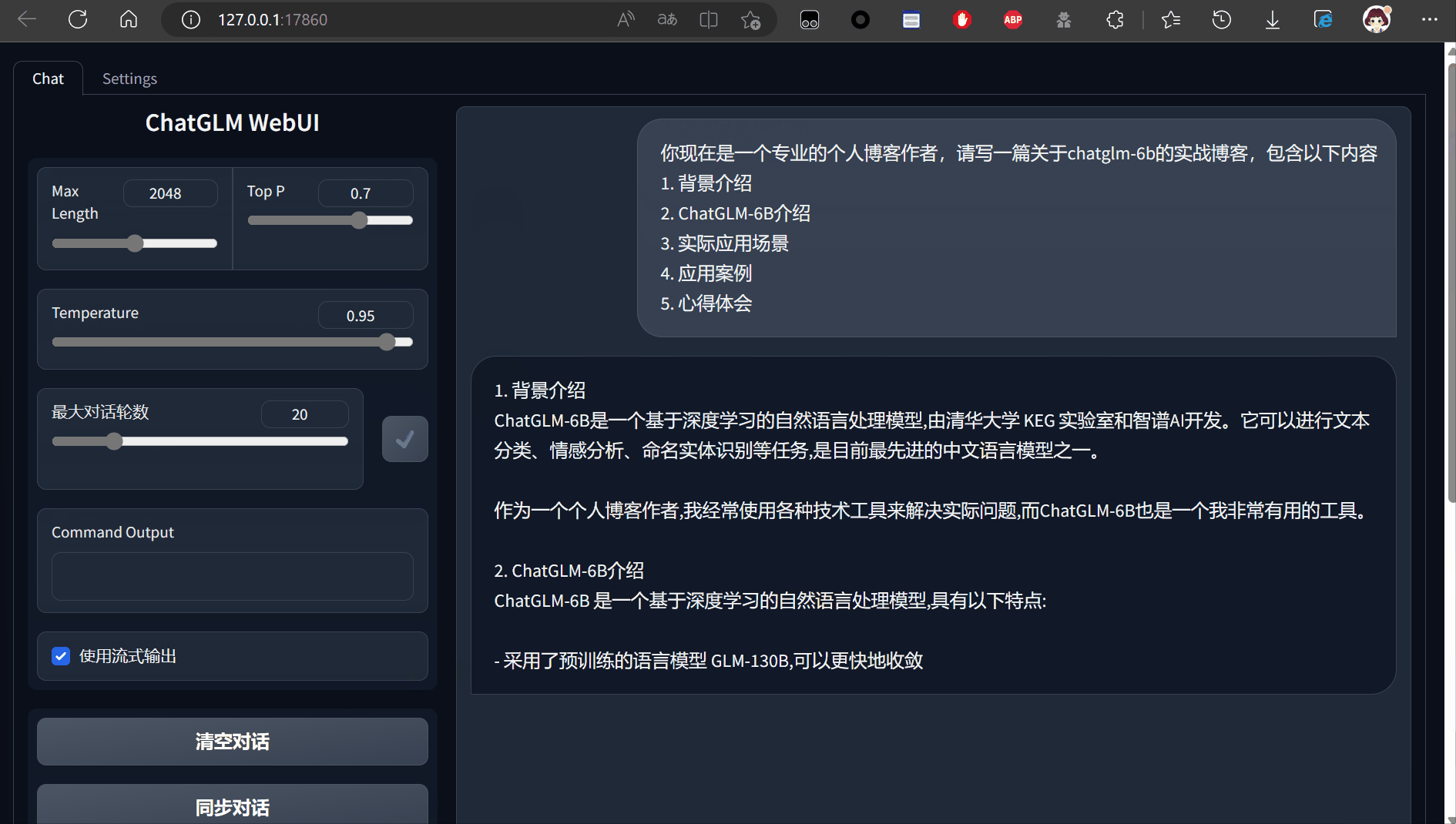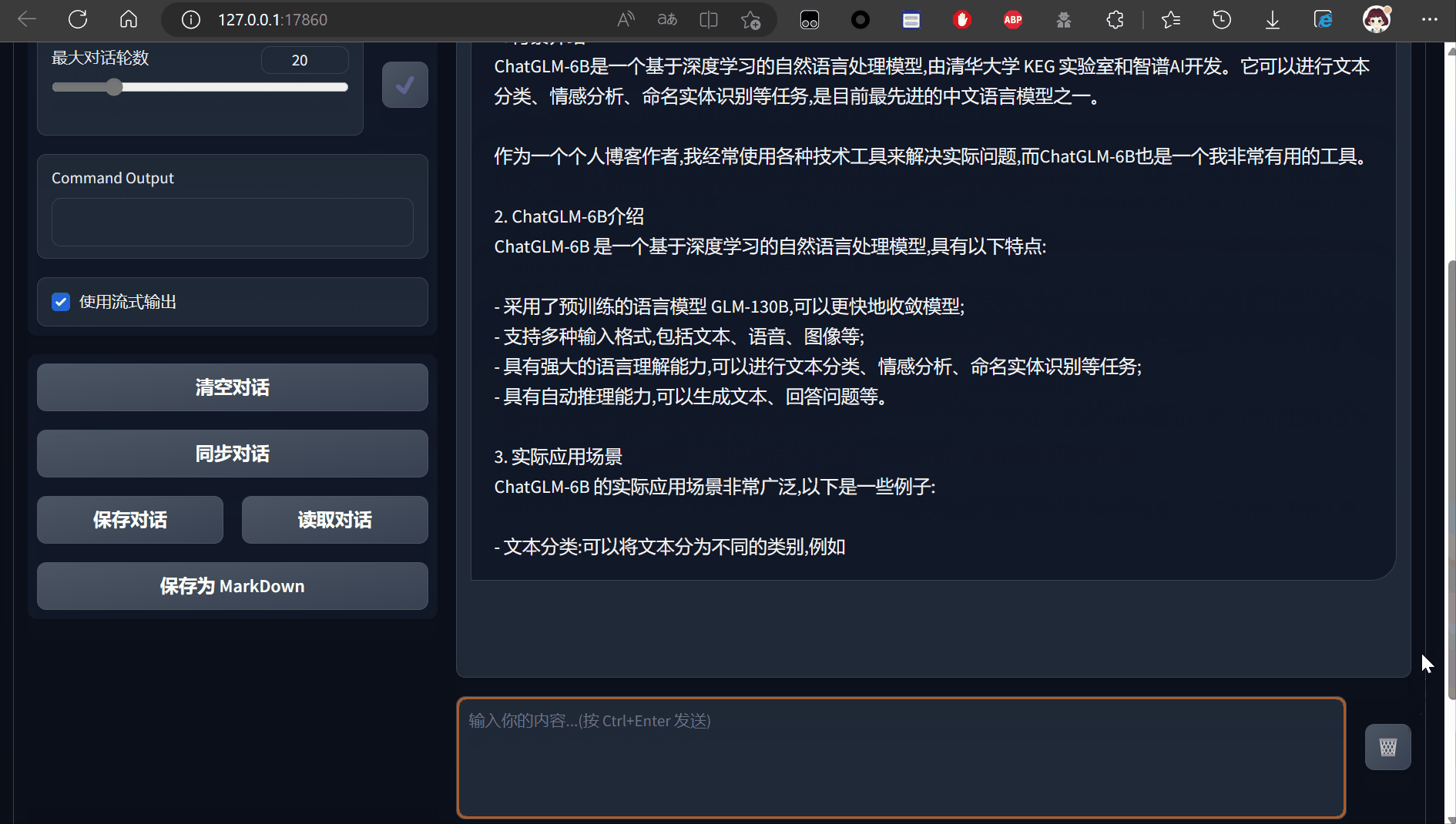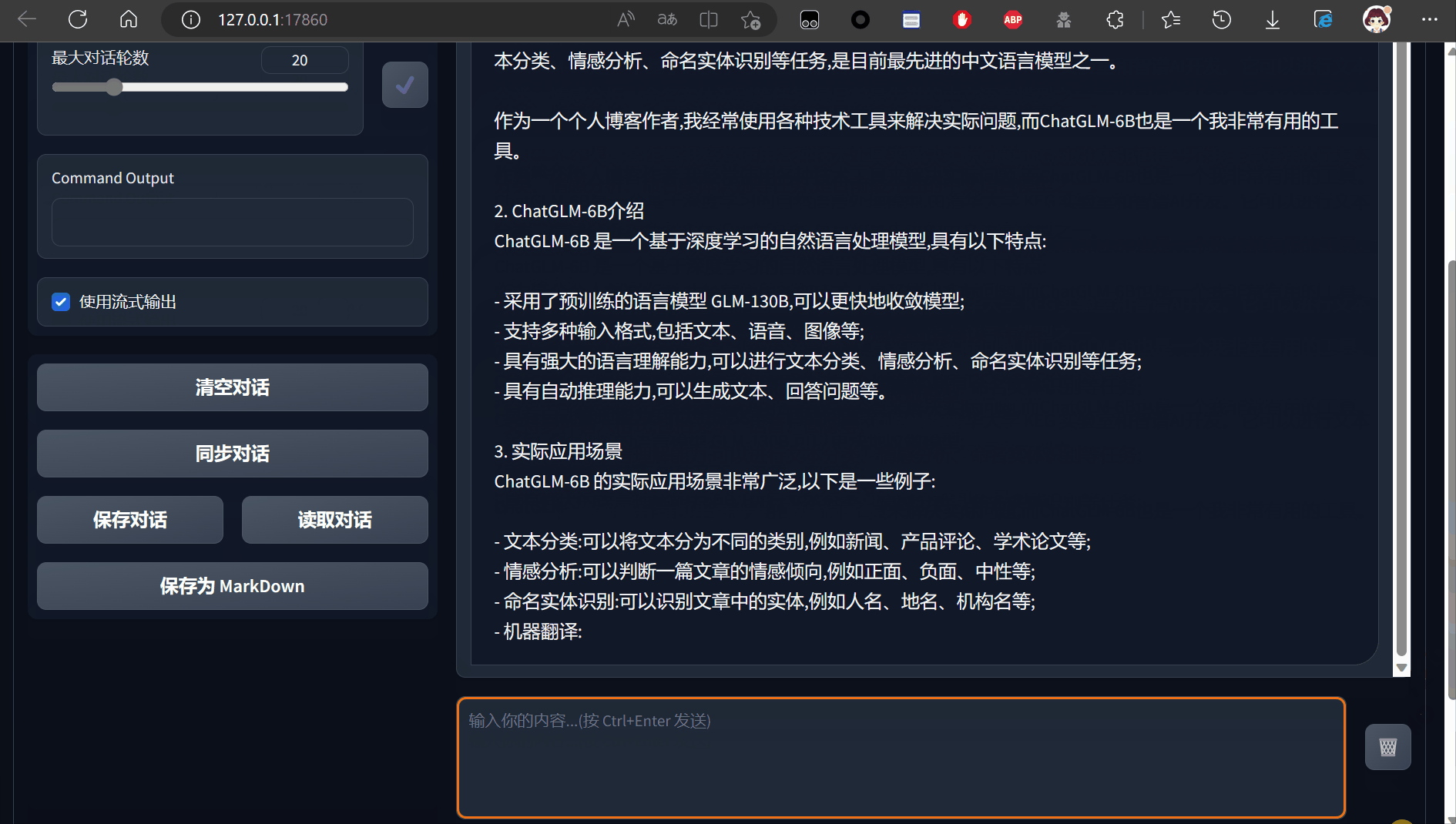
对话
对话流畅度与chatgpt类似,精准度不如gpt4
由于显存限制,咨询过大的问题会直接导致爆显存无法回答

实践-闻达版本
介绍
GitHub - wenda-LLM/wenda: 闻达:一个LLM调用平台。为小模型外挂知识库查找和设计自动执行动作,实现不亚于于大模型的生成能力
闻达基于GLM-6B扩展,支持了本地知识库和联网知识库,提供了近似new bing的体验
部署
使用官方一键包,默认使用6g显存模型
启动成功
对话-离线
只使用已有模型数据,询问
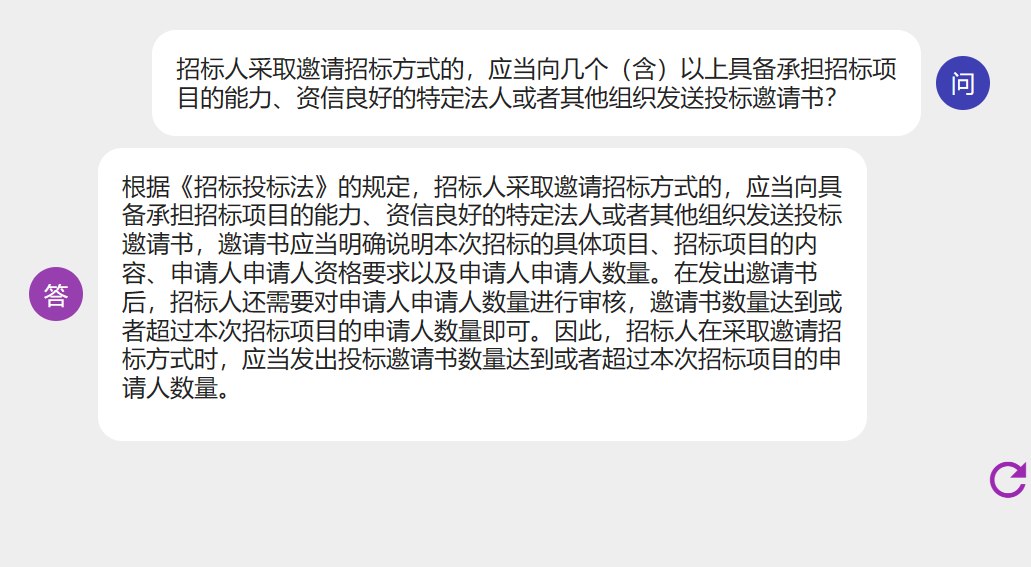
回答内容文不对题
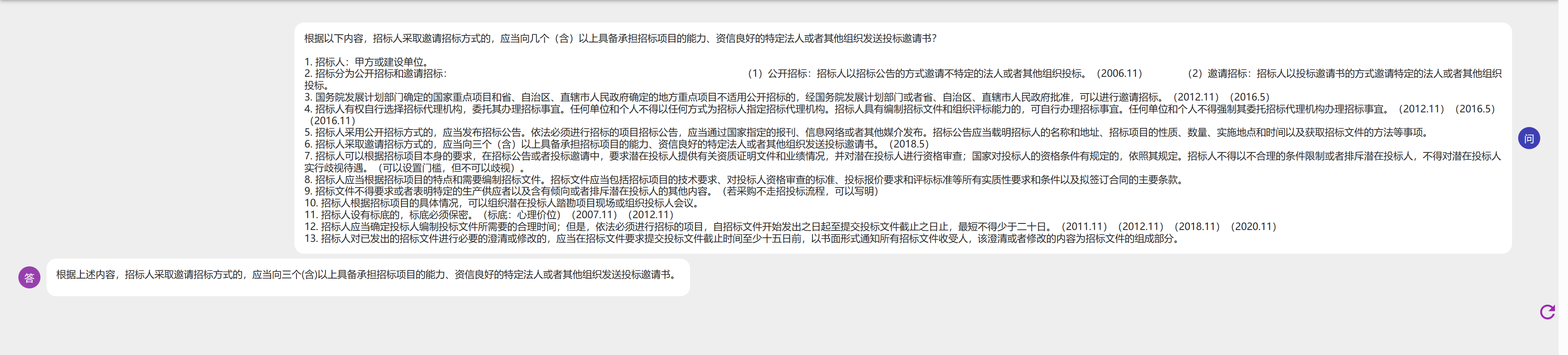
主动提供正确数据内容后再询问,此时回答正确
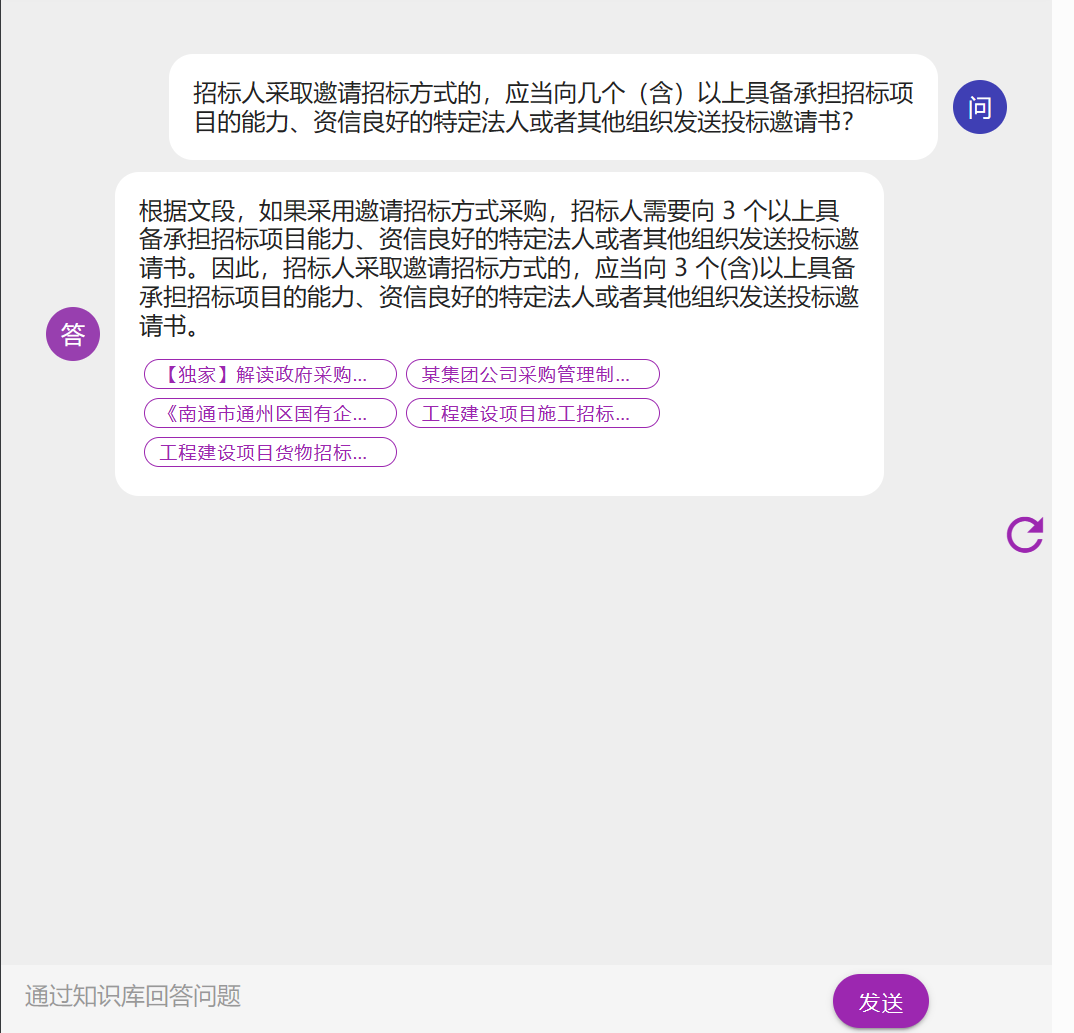
对话-使用在线知识库
打开联网知识库,清理历史后重新询问,不需要提供本地知识也可以自行通过网络检索后回答正确
系统设计问题
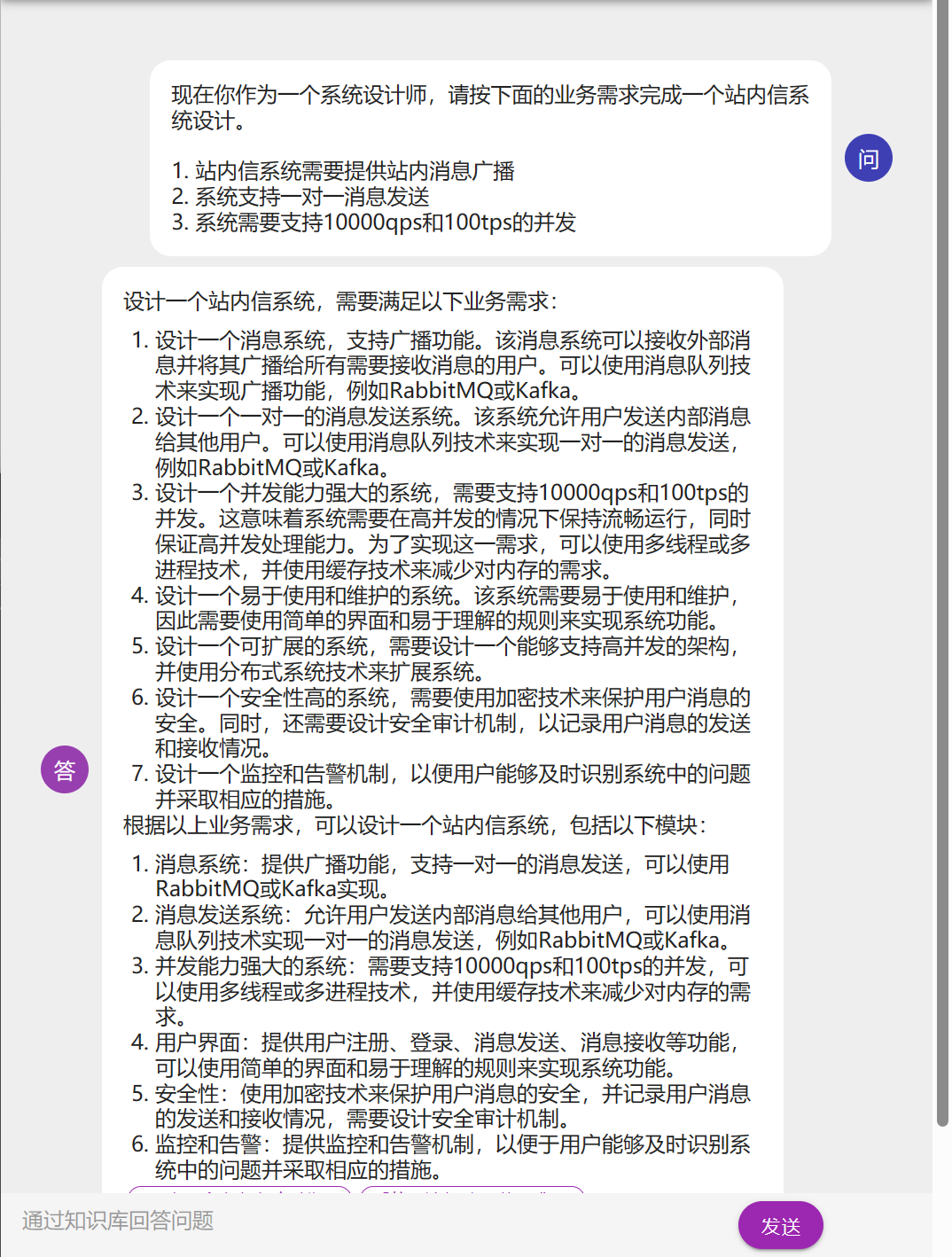
文档解析
直接读取文档
直接使用读取文档并对话的方式很容易脱离文档内容,导致答非所问
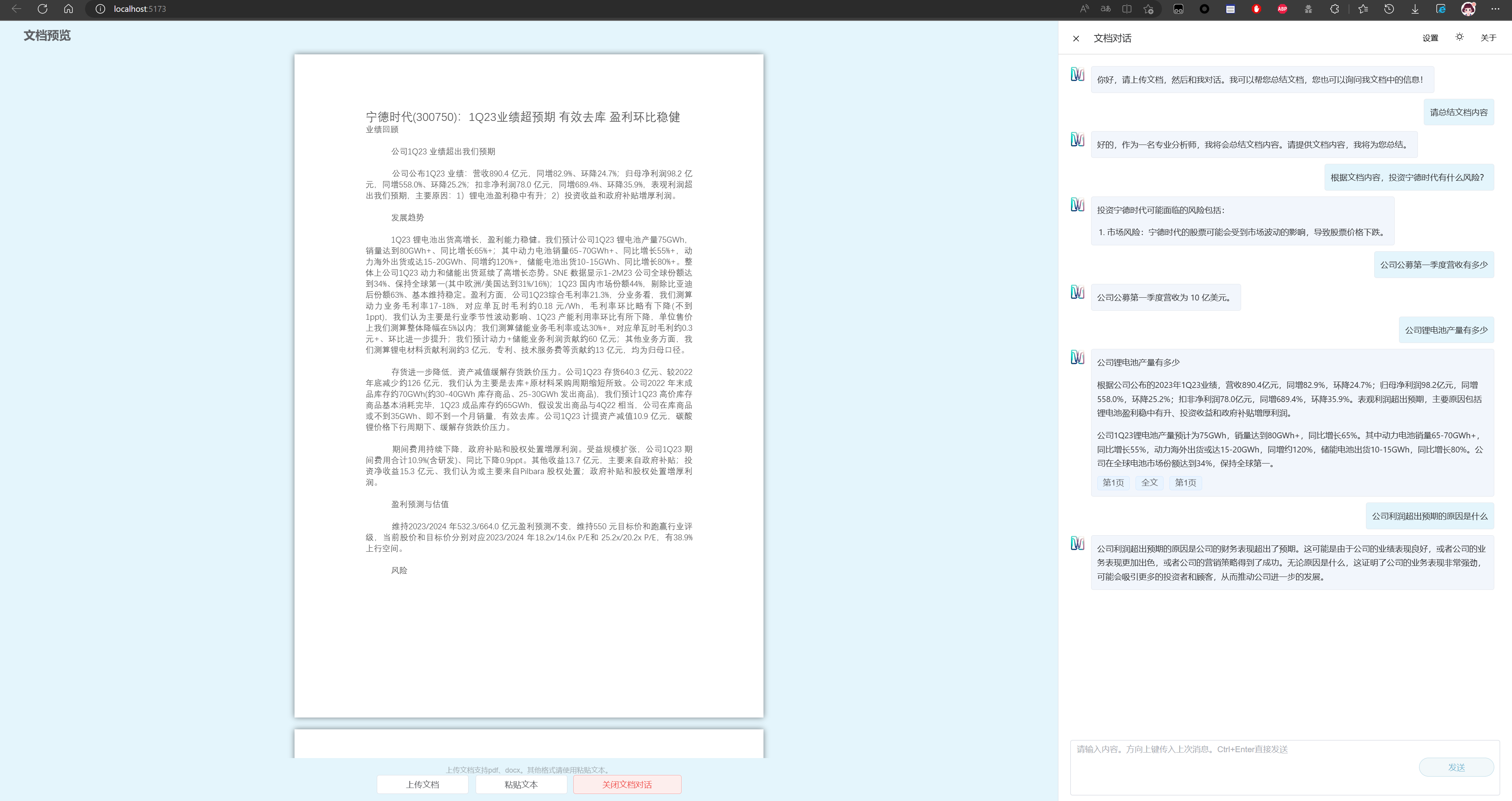
尽管使用的是6g显存的版本,读取较大的文档时也会爆显存

手动模拟文档读取
GLM文档分析实际上是将文档识别后转换为特定prompt进行问答对话
参考内嵌prompt
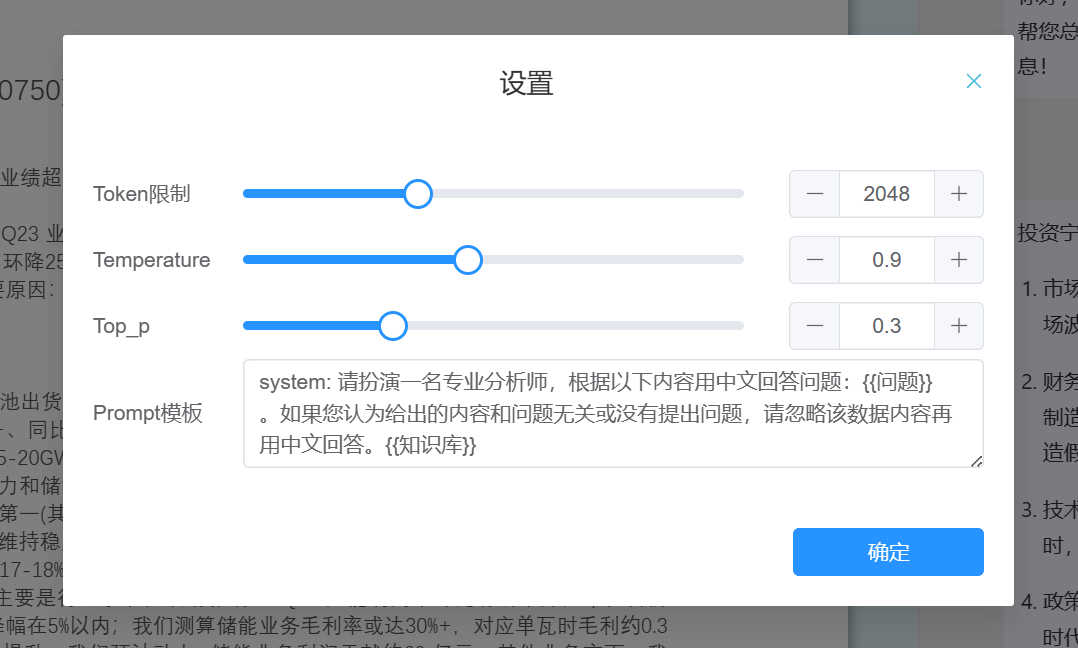
手动复制文档内容进行模拟对话,内容回答正确
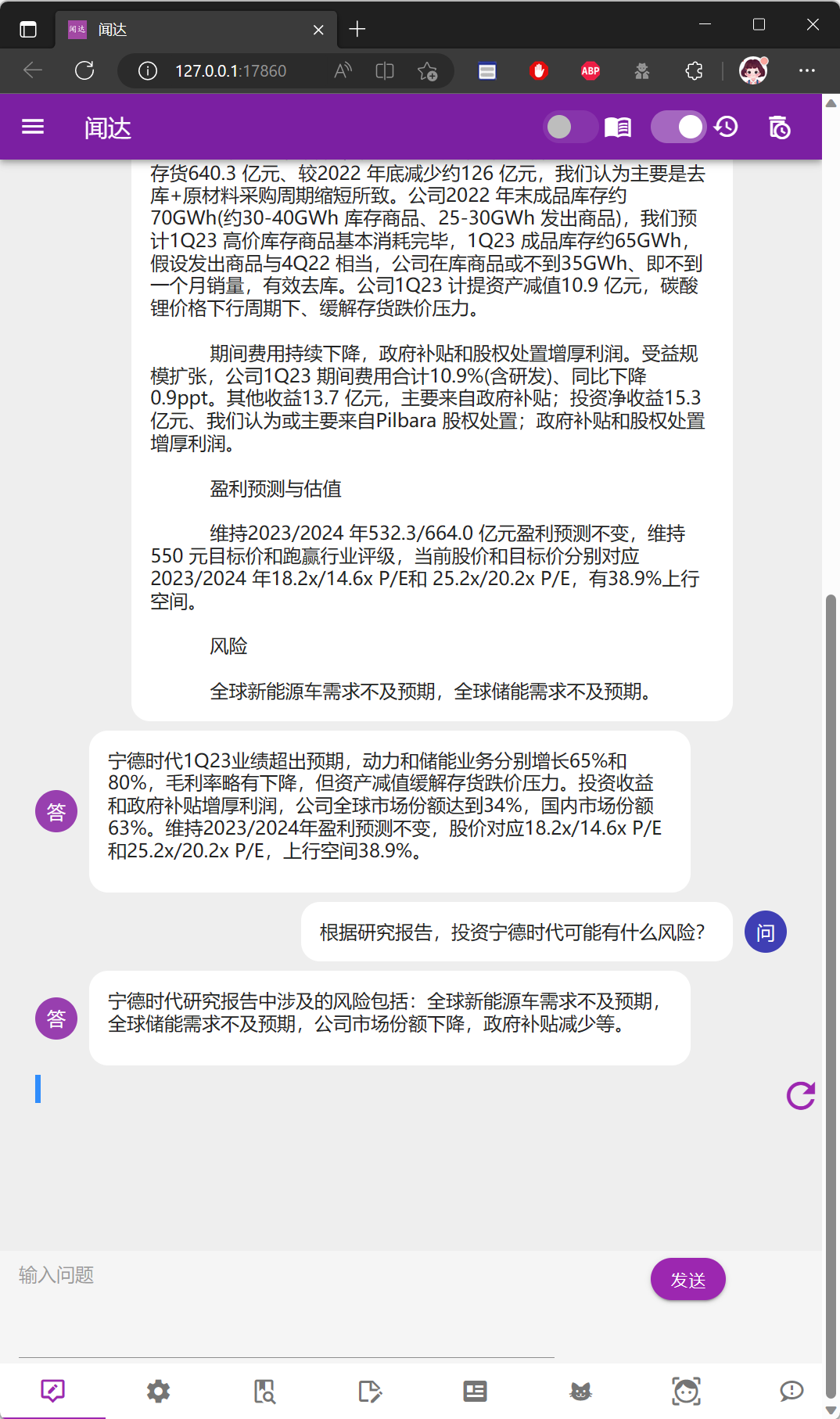
类AutoGPT功能
使用wenda提供的“根据标题写论文功能”可自动触发AutoGPT模式
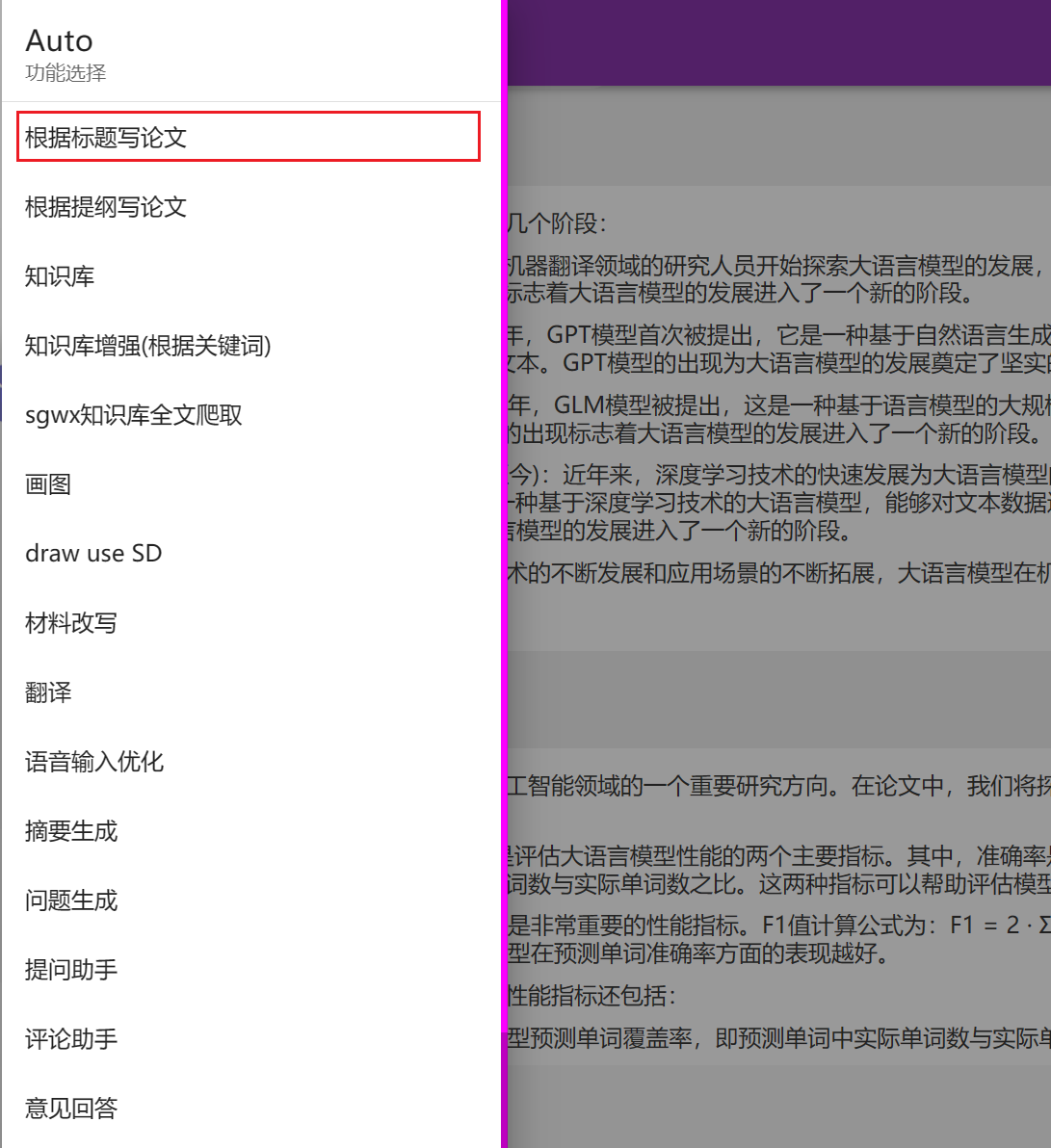
其会自己列提纲,并逐个扩展,无需手工操作
总结
在消费级甜品卡上已经能实现接近chatgpt3的能力,ChatGLM-130B更是拥有1300亿参数的中英双语稠密模型,在能力上更进一步。
未来GLM企业级私有化部署可能会被包装为简单易用的产品向政府、企业推广,满足数据保密要求。
