配置YARN
首先启动之前配置好的HDFS服务,然后进入/www/hadoop/hadoop-2.6.0-cdh5.7.0/etc/hadoop目录,按照官方指导配置YARN单节点环境
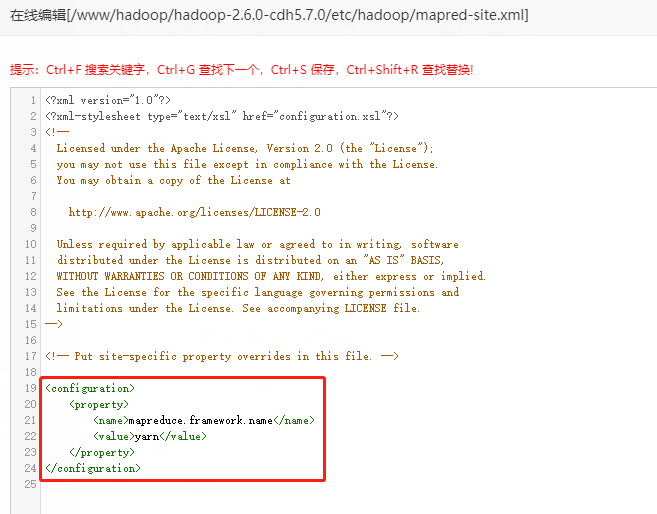
使用cp mapred-site.xml.template mapred-site.xml命令把mapred-site.xml.template复制一份,加入官方的配置
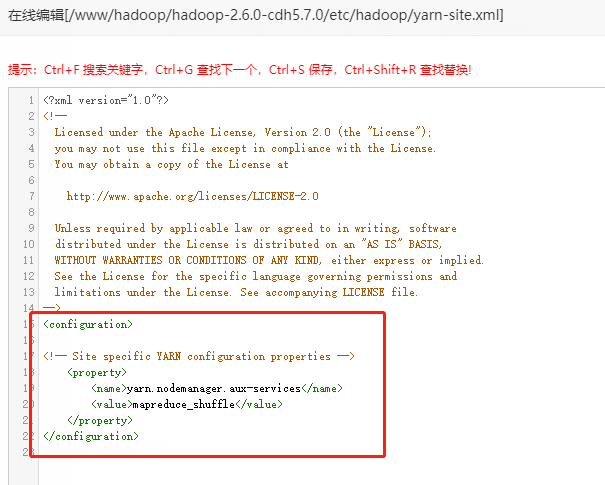
同时对yarn-site.xml也进行配置
启动YARN
进入/www/hadoop/hadoop-2.6.0-cdh5.7.0/sbin目录,使用./start-yarn.sh命令启动YARN服务
[hadoop@localhost sbin]$ ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-localhost.localdomain.out
用jps命令查看是否启动成功,看到如下显示即为启动成功,主要是NodeManager和ResourceManager两个服务
[hadoop@localhost sbin]$ jps
7056 SecondaryNameNode
7475 NodeManager
6775 NameNode
6872 DataNode
7374 ResourceManager
7679 Jps
开放端口
YARN的浏览器客户端占用8088端口,故使用宝塔面板开放8088端口

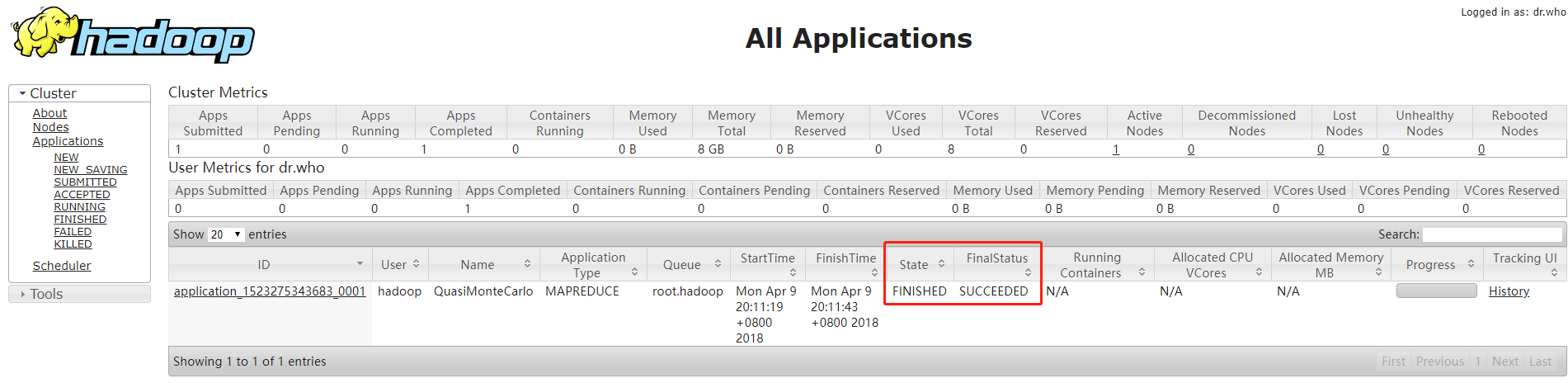
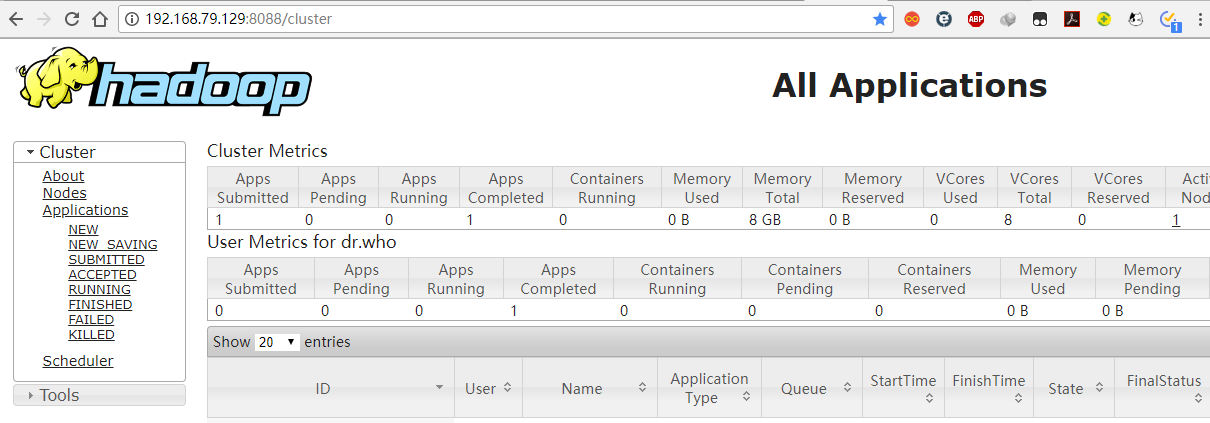
访问YARN图形化界面
使用浏览器打开http://ip:8088/可见如下界面,则YARN启动成功
测试
YARN官方提供了示例java程序来测试资源调度,进入/www/hadoop/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce目录,可见
[hadoop@localhost mapreduce]$ ls
hadoop-mapreduce-client-app-2.6.0-cdh5.7.0.jar hadoop-mapreduce-client-nativetask-2.6.0-cdh5.7.0.jar
hadoop-mapreduce-client-common-2.6.0-cdh5.7.0.jar hadoop-mapreduce-client-shuffle-2.6.0-cdh5.7.0.jar
hadoop-mapreduce-client-core-2.6.0-cdh5.7.0.jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar
hadoop-mapreduce-client-hs-2.6.0-cdh5.7.0.jar lib
hadoop-mapreduce-client-hs-plugins-2.6.0-cdh5.7.0.jar lib-examples
hadoop-mapreduce-client-jobclient-2.6.0-cdh5.7.0.jar sources
hadoop-mapreduce-client-jobclient-2.6.0-cdh5.7.0-tests.jar
其中hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar就是MapReduce的测试程序,通过hadoop jar的方式来运行
用命令查看可配置的参数hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar
[hadoop@localhost mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
[hadoop@localhost mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi
Usage: org.apache.hadoop.examples.QuasiMonteCarlo
Generic options supported are
-conf specify an application configuration file
-D use value for given property
-fs specify a namenode
-jt specify a ResourceManager
-files specify comma separated files to be copied to the map reduce cluster
-libjars specify comma separated jar files to include in the classpath.
-archives specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
从上可知测试程序可以做诸如数学π、随机文件写入等操作,这里做数学π的运算
使用命令hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 2 3做两个map计算精度为3的数学π运算,运算结束后会显示结果如下
Job Finished in 26.996 seconds
Estimated value of Pi is 4.00000000000000000000
同时浏览器也可看到作业情况