官方原理解析
MapReduce演进
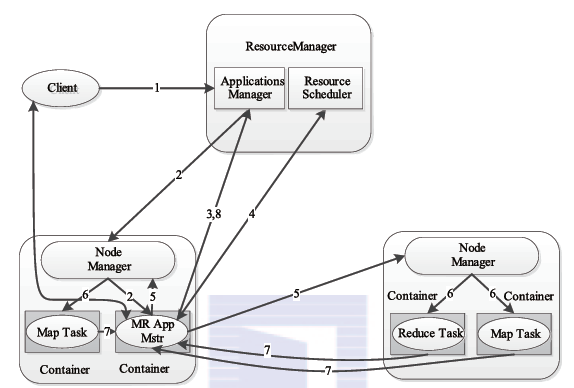
MapReduce2.x的架构
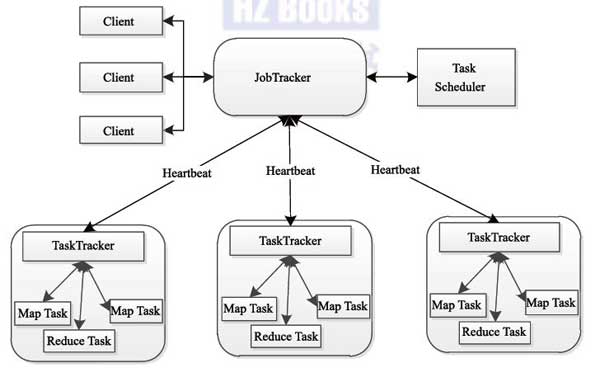
MapReduce1.x的架构,一旦JobTracker挂了,整个分布式节点就崩溃了,因此被淘汰
开发WordCount
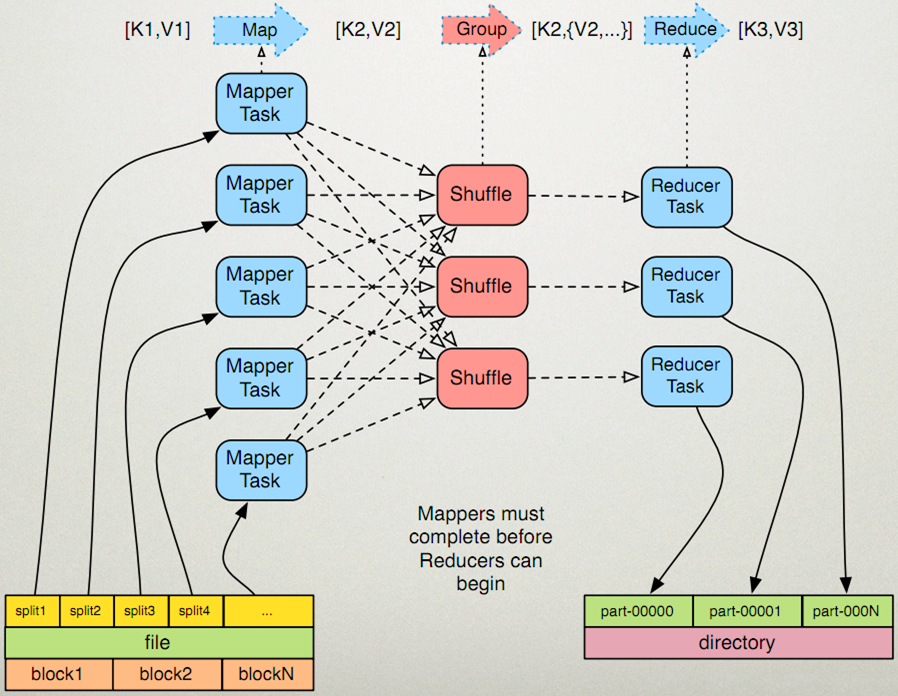
WordCount原理
数据输入到MapReduce,每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。map方法接收一个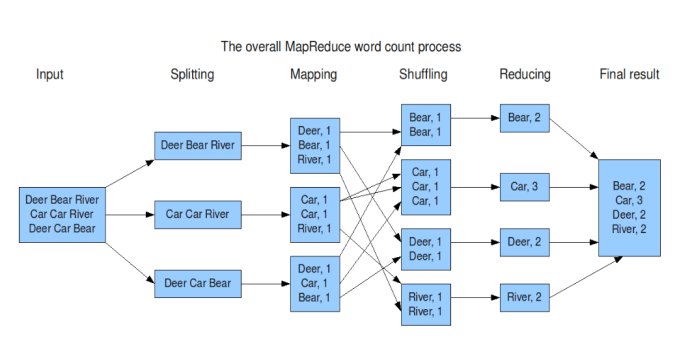
如果文本为
Hadoop Hello Hadoop
实际过程大概为:
Mapping:
,,
Shuffling:
,
Reducing:
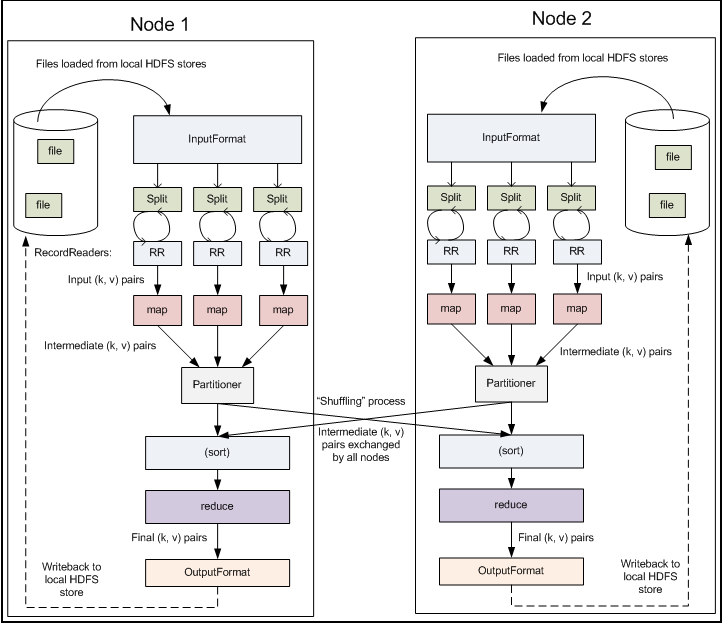
多节点下的并行计算原理示意图
开发代码
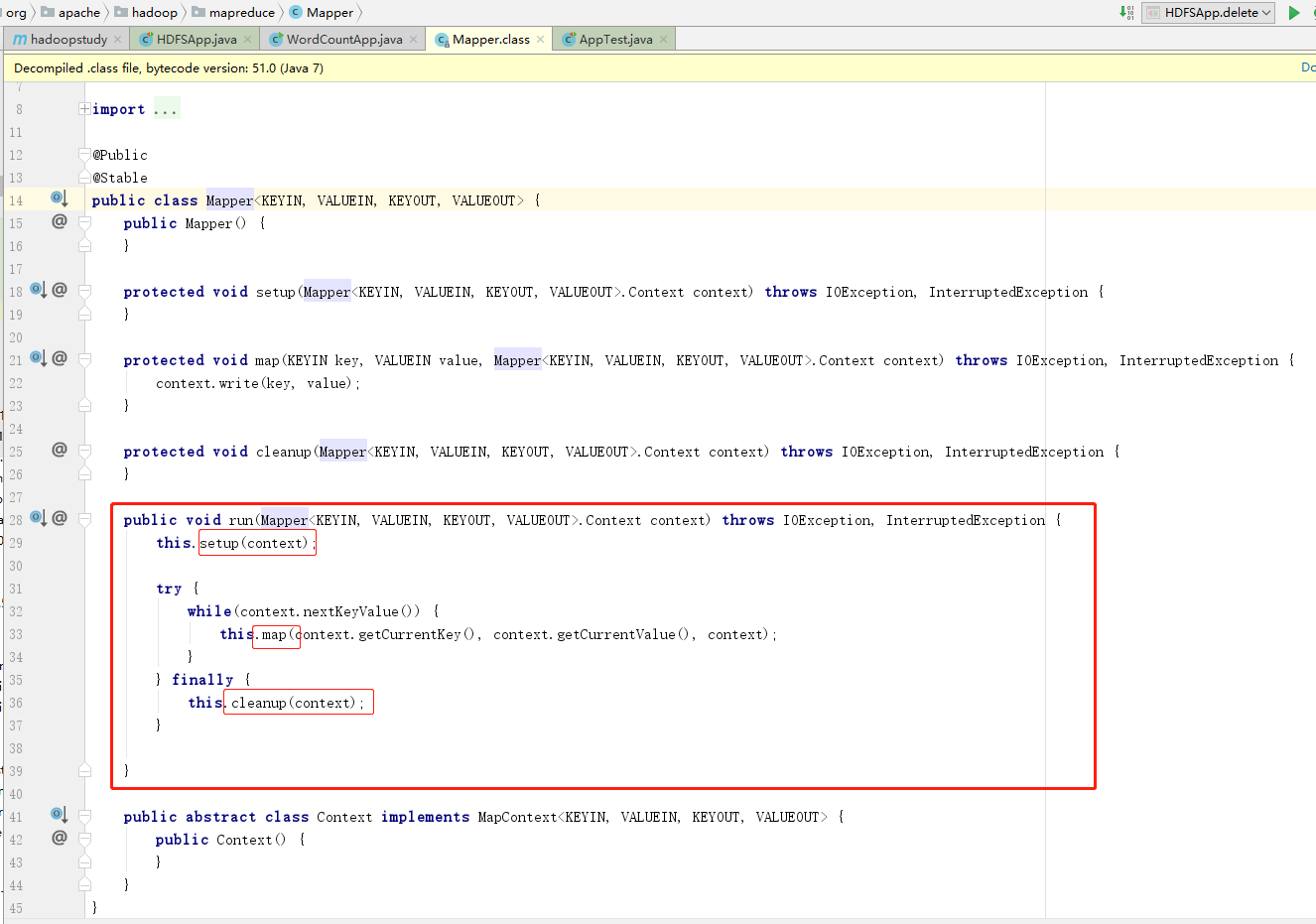
查看源码
通过查看Mapper类的源码,发现官方已经定义的run方法,包含了所有基础的Mapper操作(模板方法设计模式),主要操作在map中,因此,只要重写map方法即可。
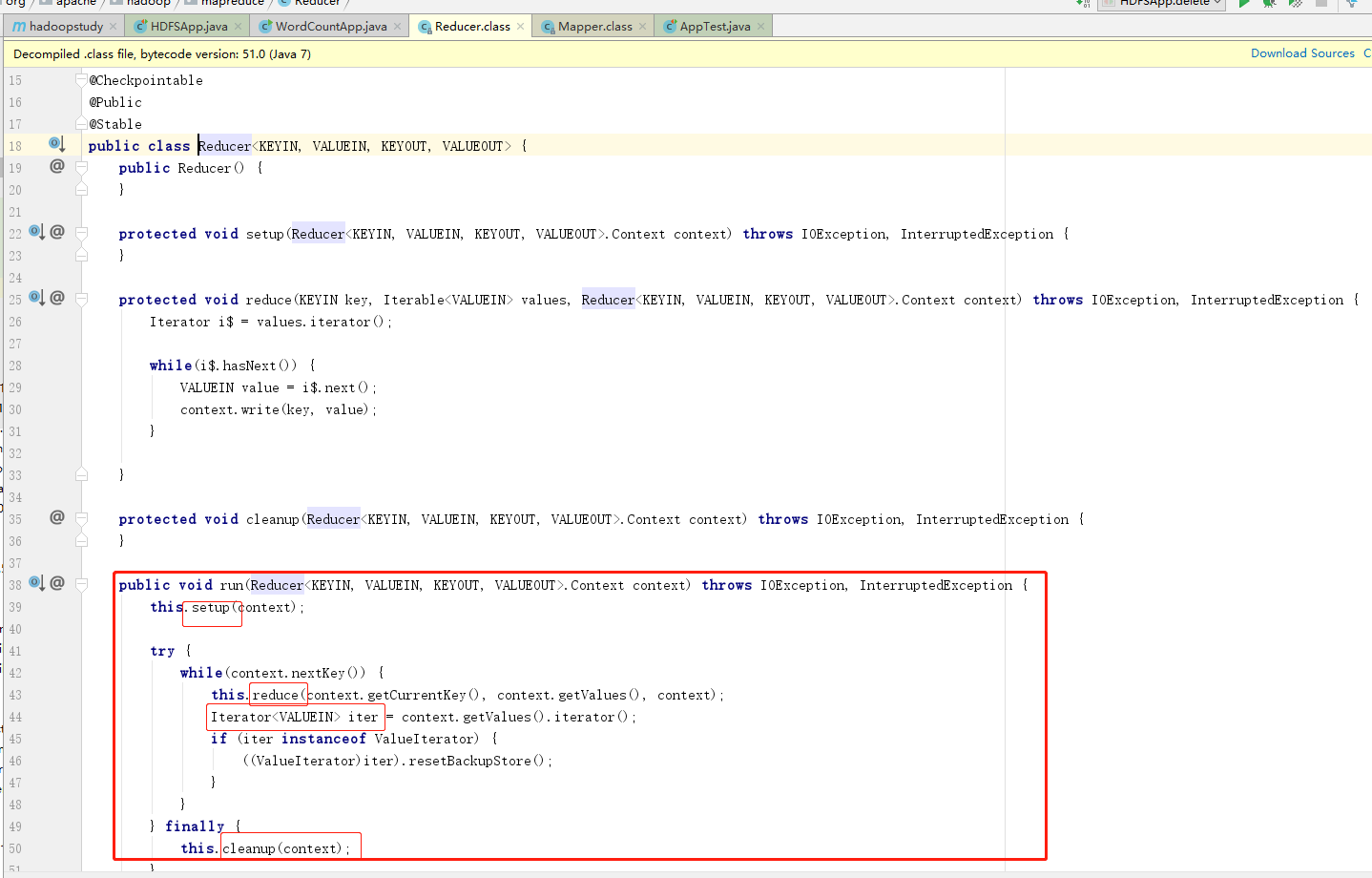
同理Reduce类中也有类似的定义
重写方法
这里只列举部分代码,其余所有代码可去本人的GitHub中查看:GitHub链接
/**
* Map:读取输入文件
* Text:类似字符串
*/
public static class MyMapper extends Mapper
LongWritable one = new LongWritable(1);
/**
* @param key 偏移量
* @param value 每行的字符串
* @param context 上下文
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/*super.map(key, value, context);*/
//接收到每一行数据
String line = value.toString();
//按照指定分隔符进行拆分
/*line.split("\t");//以Tab分隔*/
String[] words = line.split(" ");//以空格分隔
for (String word : words) {
//通过上下文把map的处理结果输出
context.write(new Text(word), one);
}
}
}
运行
通过宝塔面板上传到服务器,确保此时Hadoop所有服务均为启动状态
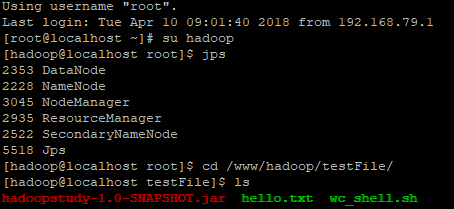
在HDFS中预先创建好要测试的文件,通过绝对路径的方法hadoop fs -ls hdfs://192.168.79.129:8020/确认文件是可以访问的
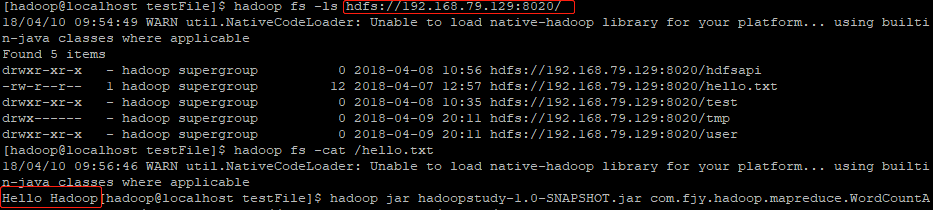
输入运行命令即可运行
hadoop jar hadoopstudy-1.0-SNAPSHOT.jar com.fjy.hadoop.mapreduce.WordCountApp hdfs://192.168.79.129:8020/hello.txt hdfs://192.168.79.129:8020/output/wc
启动至FileInputFormat
[hadoop@localhost testFile]$ hadoop jar hadoopstudy-1.0-SNAPSHOT.jar com.fjy.hadoop.mapreduce.WordCountA2.168.79.129:8020/hello.txt hdfs://192.168.79.129:8020/output/wc
18/04/10 09:57:43 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/04/10 09:57:44 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
18/04/10 09:57:45 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/04/10 09:57:45 INFO input.**FileInputFormat**: Total input paths to process : 1
执行Job
18/04/10 09:57:46 INFO mapreduce.JobSubmitter: number of splits:1
18/04/10 09:57:46 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1523322221448_0001
18/04/10 09:57:47 INFO impl.YarnClientImpl: Submitted application application_1523322221448_0001
18/04/10 09:57:47 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1523322221448_0001/
18/04/10 09:57:47 INFO mapreduce.Job: Running job: job_1523322221448_0001
18/04/10 09:57:56 INFO mapreduce.Job: Job job_1523322221448_0001 running in uber mode : false
18/04/10 09:57:56 INFO mapreduce.Job: map 0% reduce 0%
18/04/10 09:58:04 INFO mapreduce.Job: map 100% reduce 0%
18/04/10 09:58:10 INFO mapreduce.Job: map 100% reduce 100%
18/04/10 09:58:12 INFO mapreduce.Job: Job job_1523322221448_0001 completed successfully
18/04/10 09:58:12 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=39
FILE: Number of bytes written=222915
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=113
HDFS: Number of bytes written=17
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Map方法执行
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=5920
Total time spent by all reduces in occupied slots (ms)=3321
Total time spent by all map tasks (ms)=5920
Total time spent by all reduce tasks (ms)=3321
Total vcore-seconds taken by all map tasks=5920
Total vcore-seconds taken by all reduce tasks=3321
Total megabyte-seconds taken by all map tasks=6062080
Total megabyte-seconds taken by all reduce tasks=3400704
Map-Reduce Framework
Map input records=1
Map output records=2
Map output bytes=29
Map output materialized bytes=39
Reduce 方法执行
Input split bytes=101
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=39
Reduce input records=2
Reduce output records=2
Spilled Records=4
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=115
CPU time spent (ms)=1080
Physical memory (bytes) snapshot=300331008
Virtual memory (bytes) snapshot=5493092352
Total committed heap usage (bytes)=165810176
Shuffle 方法执行
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
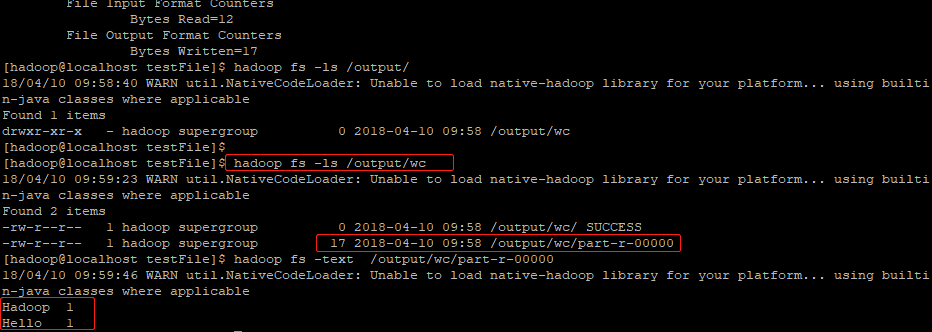
`File Input`和`File Output` 方法执行
File Input Format Counters
Bytes Read=12
File Output Format Counters
Bytes Written=17
运行结果如图
进一步优化
使用Combiner
使用Combiner组件可以在Mapping时就先进行一次聚合,再发送到Shuffling继续运算,从而提高运算效率 在主方法中进行如下配置即可
//通过job设置combiner处理类,逻辑上与reduce一致,注意,如果要计算平均数等不能使用Combiner!
job.setCombinerClass(MyReducer.class);
编写完后使用Maven重新打包
mvn clean package -DskipTests
上传到服务器后再次执行计算命令
hadoop jar hadoopstudy-0.3.jar com.fjy.hadoop.mapreduce.WordCountApp hdfs://192.168.79.129:8020/hello.txt hdfs://192.168.79.129:8020/output/wc
查看图形界面可观察是否完成
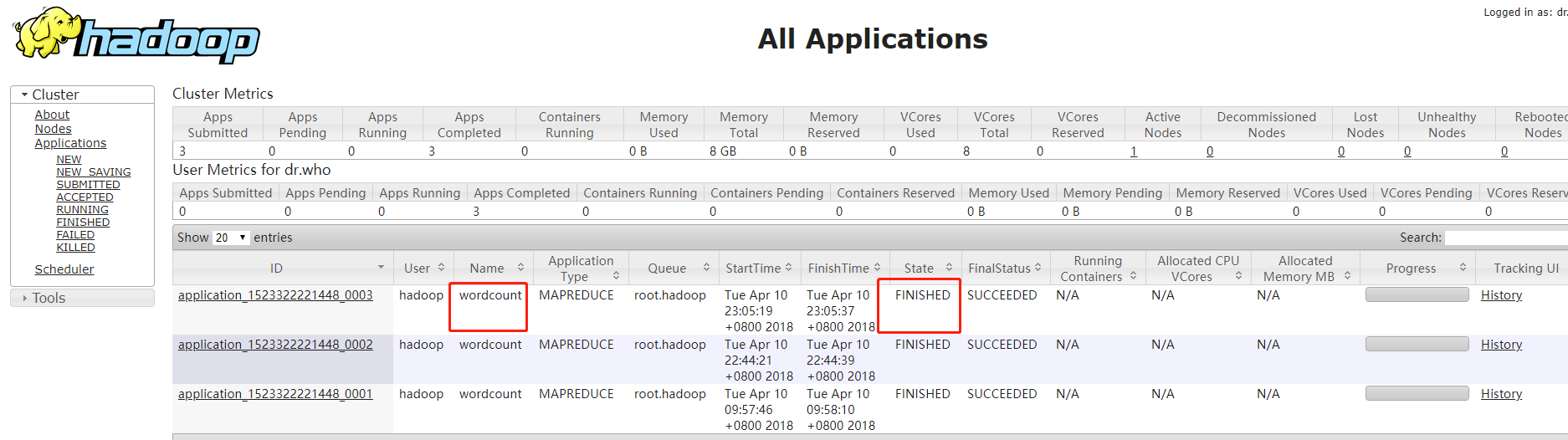
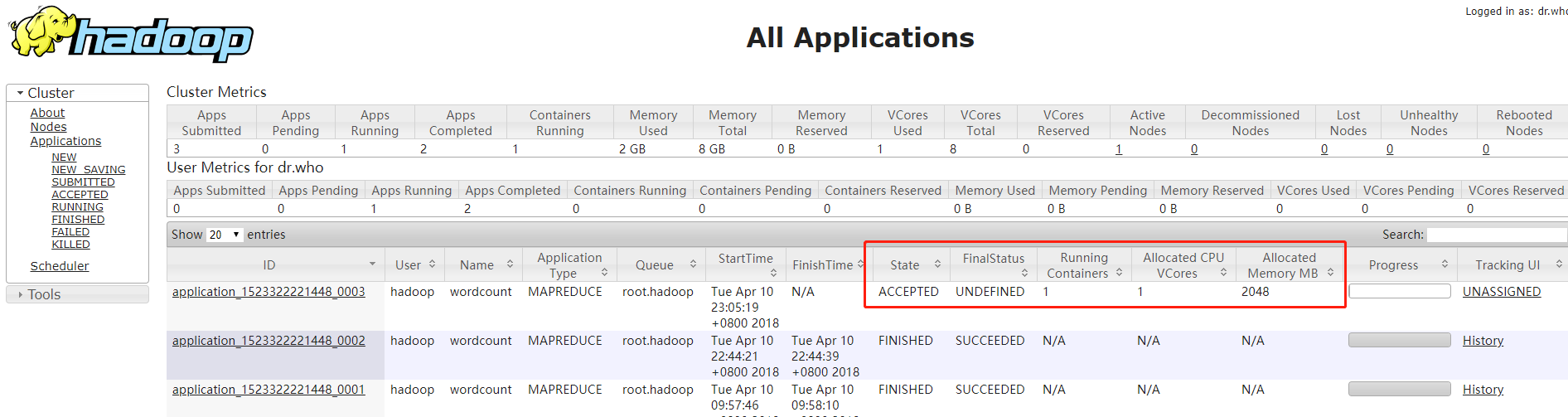
通过查看代码可发现Combine input records已经不为0(之前未使用Combiner 时该值为0),说明使用成功
Map-Reduce Framework
Map input records=4
...
Combine input records=9
Combine output records=5
...
Physical memory (bytes) snapshot=298844160
Virtual memory (bytes) snapshot=5493088256
Total committed heap usage (bytes)=165810176
Shuffle Errors
BAD_ID=0
...
查看结果
[hadoop@localhost testFile]$ hadoop fs -cat /output/wc/part-r-00000
18/04/10 23:06:51 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
! 1
Hadoop 3
Hello 2
MapReduce 2
YARN 1
使用Partitioner组件
作用
Partitioner决定MapTask输出的数据交由哪个ReduceTask处理,其默认实现为分发的key的hash值对ReduceTask个数取模
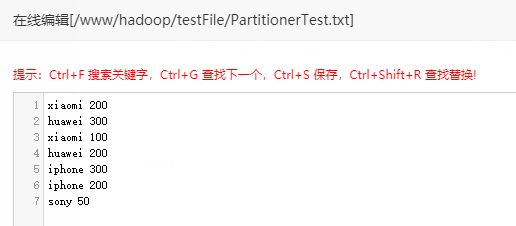
文件准备
在宝塔测试目录/www/hadoop/testFile下准备好PartitionerTest.txt文件,文件内容如图,将其上传到HDFS根目录中
[hadoop@localhost root]$ cd /www/hadoop/testFile
[hadoop@localhost testFile]$ ls
PartitionerTest.txt hello.txt
[hadoop@localhost testFile]$ hadoop fs -put PartitionerTest.txt /
18/04/11 00:30:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@localhost testFile]$ hadoop fs -ls /
18/04/11 00:30:39 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 7 items
-rw-r--r-- 1 hadoop supergroup 73 2018-04-11 00:30 /PartitionerTest.txt
drwxr-xr-x - hadoop supergroup 0 2018-04-08 10:56 /hdfsapi
-rw-r--r-- 1 hadoop supergroup 60 2018-04-10 23:03 /hello.txt
drwxr-xr-x - hadoop supergroup 0 2018-04-10 23:05 /output
drwxr-xr-x - hadoop supergroup 0 2018-04-08 10:35 /test
drwx------ - hadoop supergroup 0 2018-04-09 20:11 /tmp
drwxr-xr-x - hadoop supergroup 0 2018-04-09 20:11 /user
[hadoop@localhost testFile]$ hadoop fs -text /PartitionerTest.txt
18/04/11 00:30:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
xiaomi 200
huawei 300
xiaomi 100
huawei 200
iphone 300
iphone 200
sony 50
代码编写
主要对分隔符和上下文内容进行修改,map类中修改为
//每一个空格是一个手机品牌,另一个是销售数量
context.write(new Text(words[0]), new LongWritable(Long.parseLong(words[1])));
新增Partitioner处理类
/**
* Partitioner处理类
*/
public static class MyPartitioner extends Partitioner{
@Override
public int getPartition(Text key, LongWritable value, int i) {
if ("xiaomi".equals(key.toString())) {
return 0;//若为xiaomi则交由0 ReduceTask处理
}
if ("huawei".equals(key.toString())) {
return 1;//若为huawei则交由1 ReduceTask处理
}
if ("iphone".equals(key.toString())) {
return 2;//若为iphone则交由2 ReduceTask处理
}
return 3;//若为其他,则交由3 ReduceTask处理
}
}
最后在驱动中配置Partitioner
//设置job的Partition
job.setPartitionerClass(MyPartitioner.class);
//设置四个reducer,每个分区一个,否则Partitioner配置不生效
job.setNumReduceTasks(4);
通过复制类名全路径(以IDEA为例),修改运行命令
此时,运行命令为
hadoop jar hadoopstudy-0.4.jar com.fjy.hadoop.mapreduce.WordCountPartitionerApp hdfs://192.168.79.129:8020/PartitionerTest.txt hdfs://192.168.79.129:8020/output/partitioner
执行
再次用Maven打包并上传到测试目录运行
运行前:
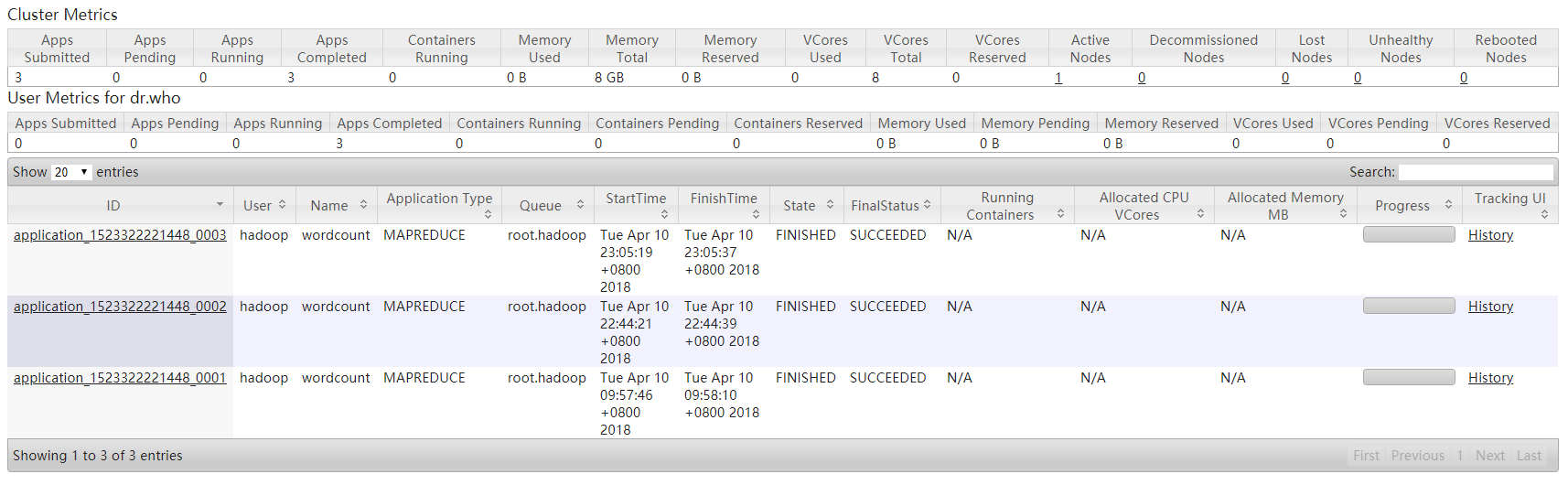
运行中:
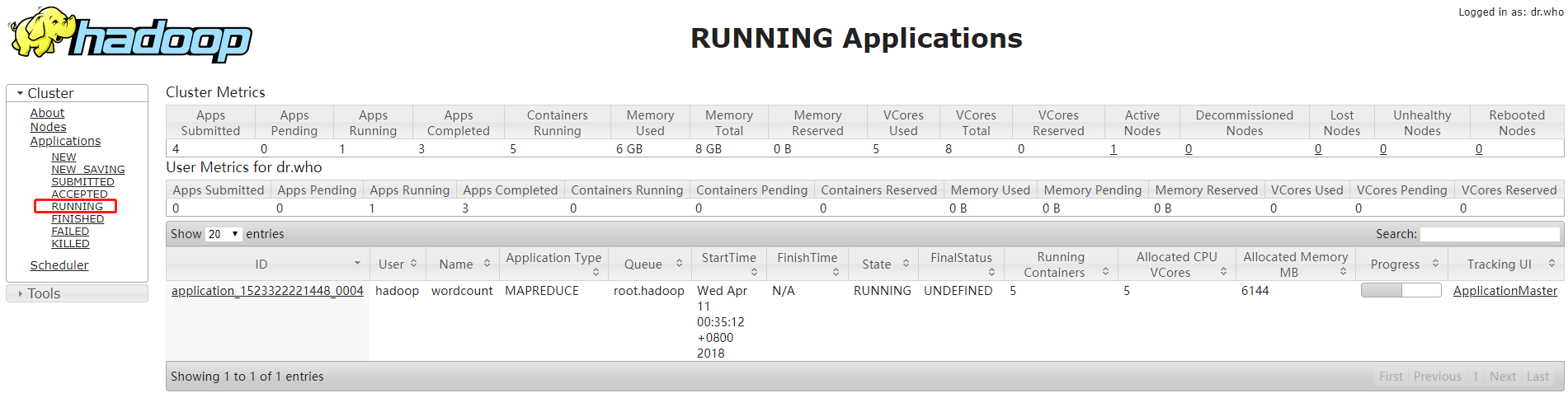
运行结束
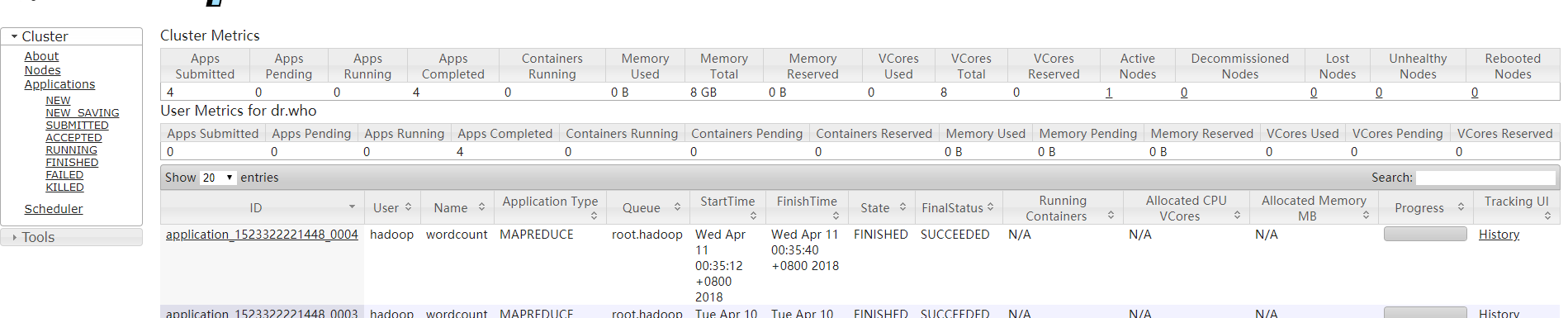
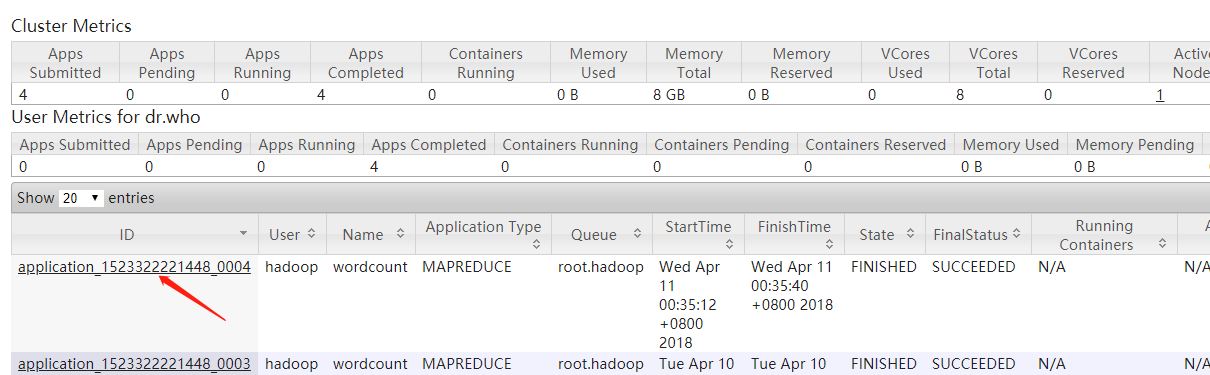
查看结果内容:
[hadoop@localhost testFile]$ hadoop fs -ls /output/partitioner
18/04/11 00:36:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 5 items
-rw-r--r-- 1 hadoop supergroup 0 2018-04-11 00:35 /output/partitioner/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 11 2018-04-11 00:35 /output/partitioner/part-r-00000
-rw-r--r-- 1 hadoop supergroup 11 2018-04-11 00:35 /output/partitioner/part-r-00001
-rw-r--r-- 1 hadoop supergroup 11 2018-04-11 00:35 /output/partitioner/part-r-00002
-rw-r--r-- 1 hadoop supergroup 8 2018-04-11 00:35 /output/partitioner/part-r-00003
[hadoop@localhost testFile]$ hadoop fs -text /output/partitioner/part-r-00000
18/04/11 00:36:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
xiaomi 300
[hadoop@localhost testFile]$ hadoop fs -text /output/partitioner/part-r-00001
18/04/11 00:36:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
huawei 500
[hadoop@localhost testFile]$ hadoop fs -text /output/partitioner/part-r-00002
18/04/11 00:37:05 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
iphone 500
[hadoop@localhost testFile]$ hadoop fs -text /output/partitioner/part-r-00003
18/04/11 00:37:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
sony 50
结果正确!
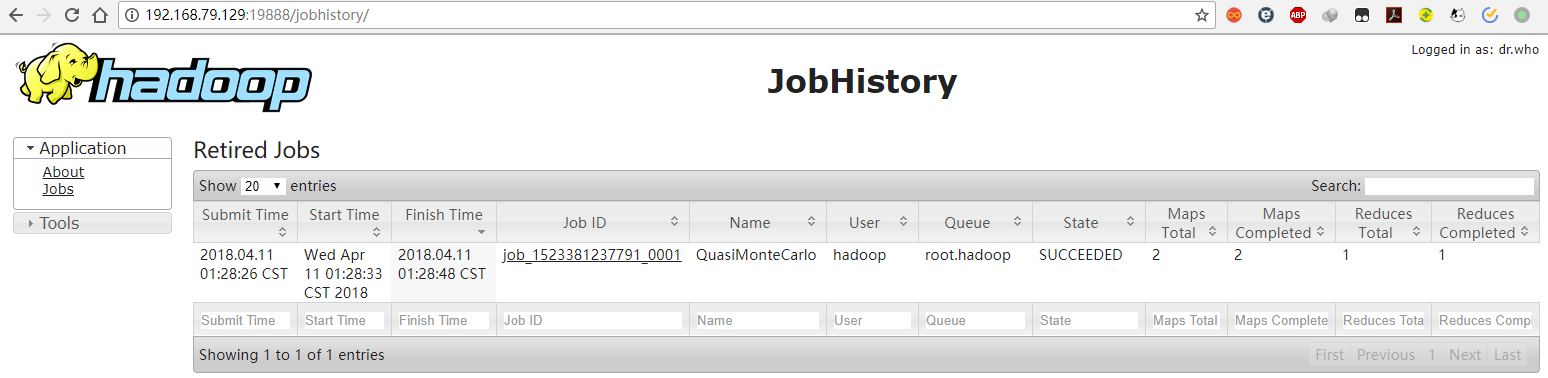
开启JobHistory
JobHistory作用
记录已经运行完 的MapReduce信息到指定的HDFS目录下,但默认不开启 因此此时不配置直接访问如下
![jobhistory][33]
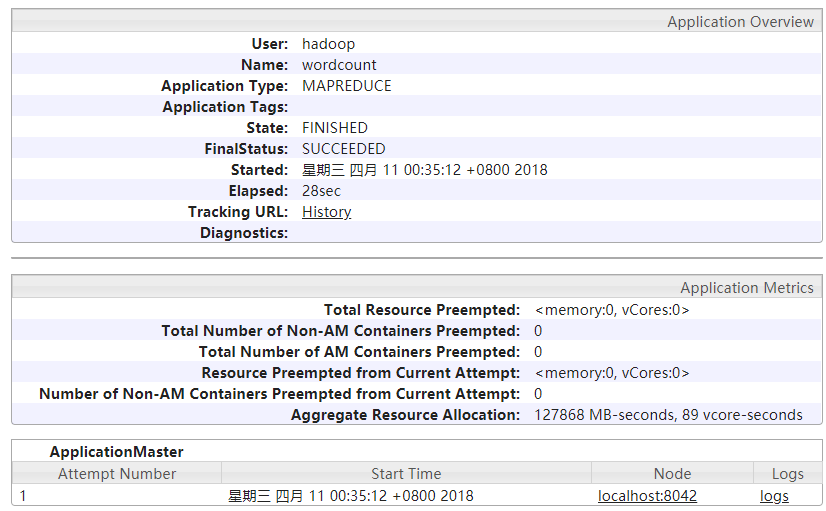
配置JobHistory
在mapred-site.xml加入配置
mapreduce.jobhistory.address
192.168.79.129:10020
MapReduce JobHistory Server IPC host:port
mapreduce.jobhistory.webapp.address
192.168.79.129:19888
MapReduce JobHistory Server Web UI host:port
mapreduce.jobhistory.done-dir
/history/done
mapreduce.jobhistory.intermediate-done-dir
/history/done_intermediate

配置完后重启YARN
[hadoop@localhost mapreduce]$ cd /www/hadoop/hadoop-2.6.0-cdh5.7.0/sbin
[hadoop@localhost sbin]$ ./stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
localhost: stopping nodemanager
no proxyserver to stop
[hadoop@localhost sbin]$ jps
2353 DataNode
80224 Jps
2228 NameNode
2522 SecondaryNameNode
[hadoop@localhost sbin]$ ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-localhost.localdomain.out
[hadoop@localhost mapreduce]$ jps
2353 DataNode
80336 ResourceManager
2228 NameNode
81510 Jps
2522 SecondaryNameNode
63582 JobHistoryServer
80447 NodeManager
启动jobhistory服务
[hadoop@localhost sbin]$ ./mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/mapred-hadoop-historyserver-localhost.localdomain.out
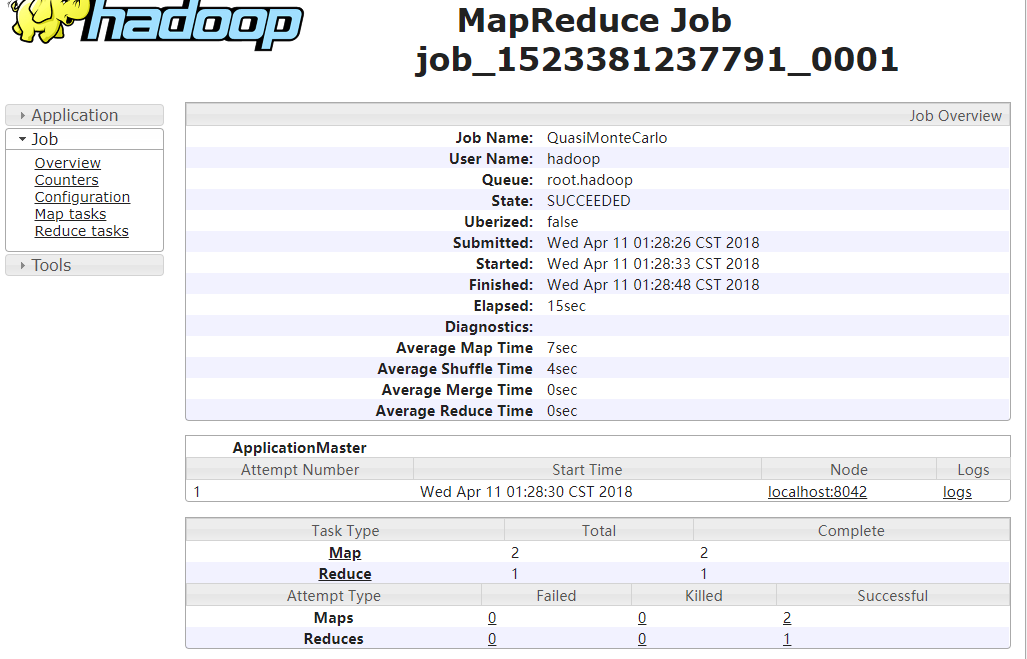
运行PI测试
[hadoop@localhost sbin]$ cd /www/hadoop/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce
[hadoop@localhost mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 1 2
访问报错
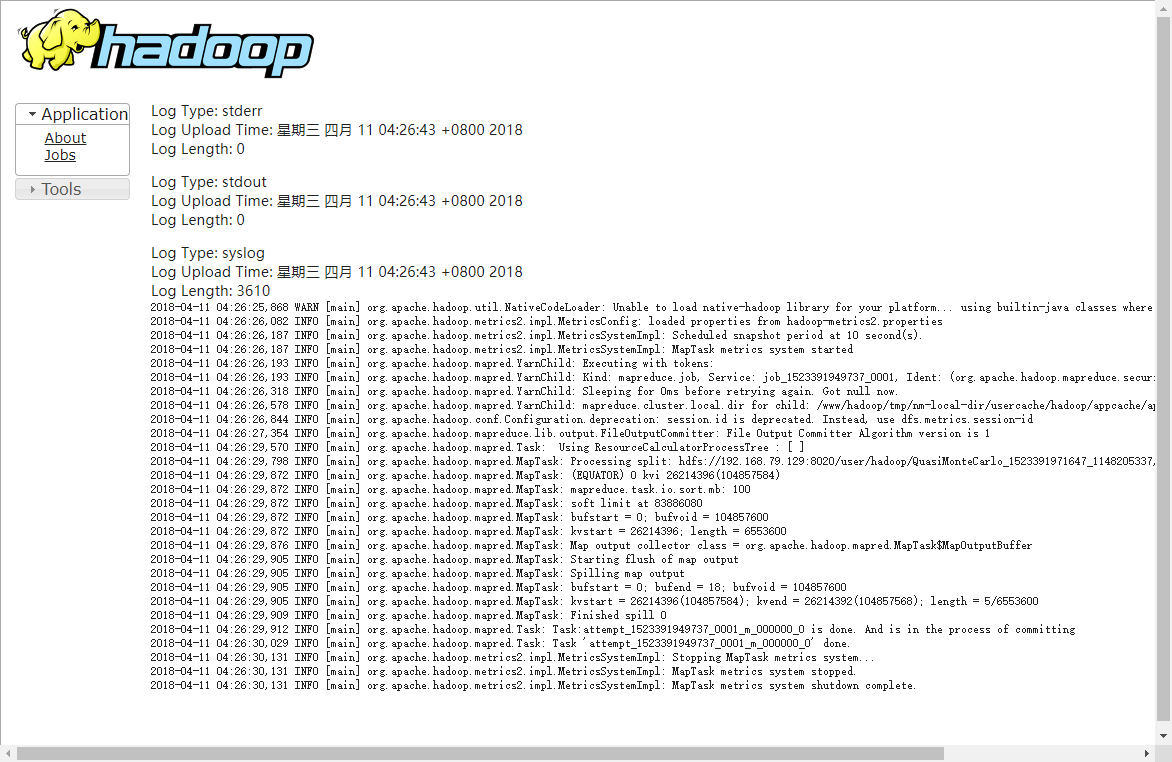
进入日志查看,发现仍然无法访问

报未开启聚合的错误,同时发现指向跳转链接为localhost

增加配置
因此在yarn-site.xml加入配置
yarn.log-aggregation-enable
true
同时,为了让虚拟机的跳转链接不为localhost,此处再加入一段配置,制定IP
yarn.nodemanager.hostname
192.168.79.129

重启服务
再次重启YARN,并同时重启jobhistory服务
[hadoop@localhost sbin]$ ./mr-jobhistory-daemon.sh stop historyserver
stopping historyserver
[hadoop@localhost sbin]$ ./stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
localhost: stopping nodemanager
no proxyserver to stop
[hadoop@localhost sbin]$ ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-localhost.localdomain.out
[hadoop@localhost sbin]$ ./mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/mapred-hadoop-historyserver-localhost.localdomain.out
【注意】此时若只重启YARN就算配置正确,仍然可能出现Aggregation is not enabled的错误
验证
再次执行PI运算
[hadoop@localhost sbin]$ cd /www/hadoop/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce
[hadoop@localhost mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 1 2
查看Logs记录
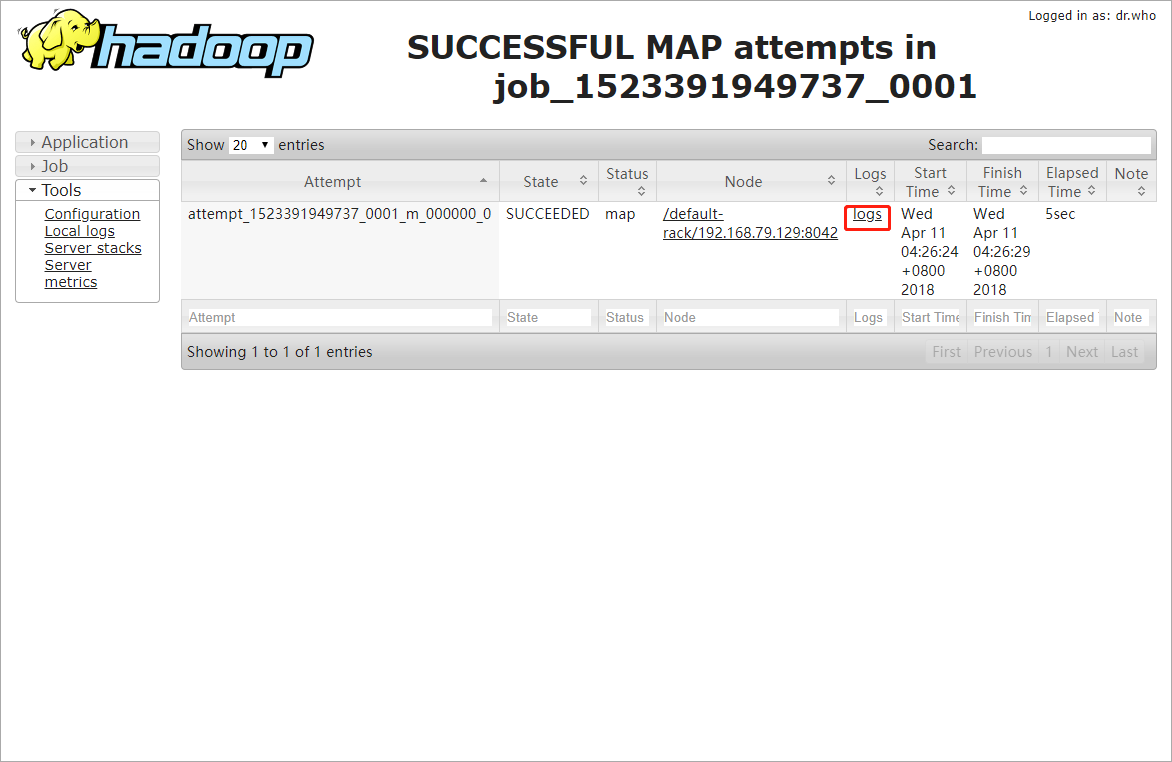
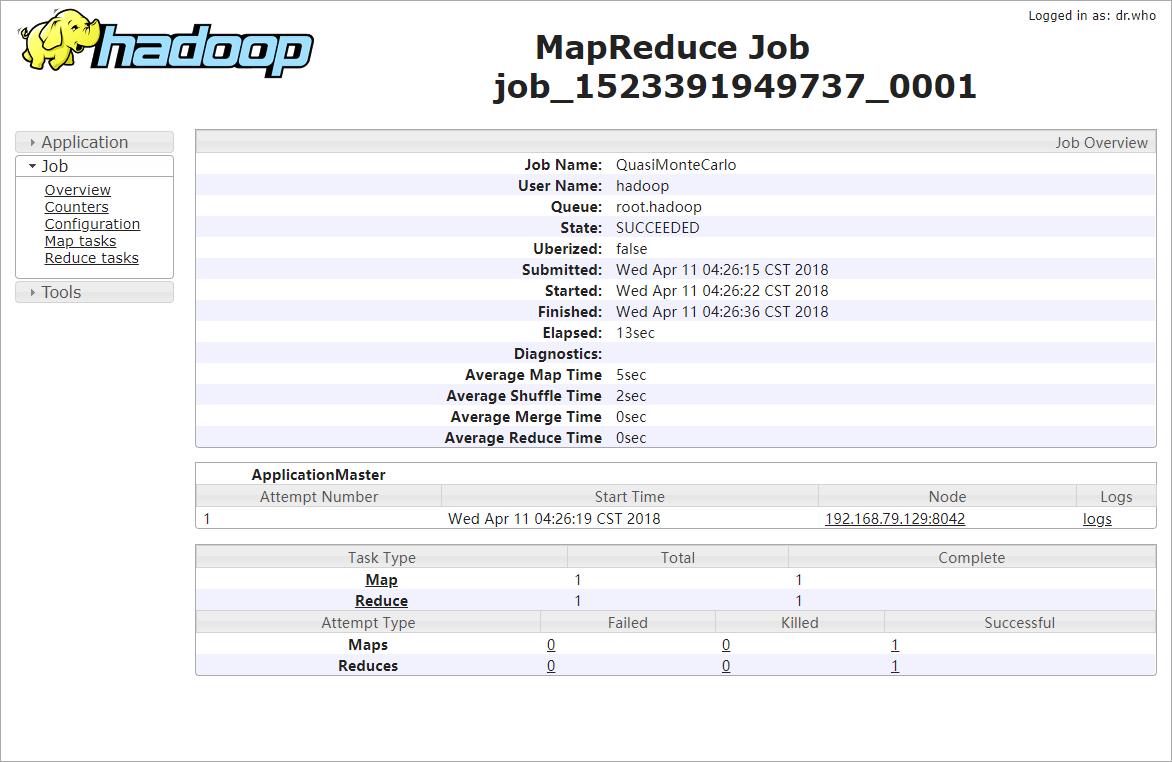
已经有日志记录,配置成功!