搭建环境
Windows VM虚拟机
虚拟机配置 CPU:7700 单核 RAM:2G SSD:20G OS:CentOS 7.4
环境配置
修改主机名
因为三台虚拟机均为一台虚拟机克隆而成,且源主机名为localhost,先计划将三台主机分别设置为hadoop0,hadoop1,hadoop2 IP、主机名、职能分别为: 192.168.79.129 hadoop0 NameNode DataNode ResourceManager NodeManager 192.168.79.130 hadoop1 DataNode NodeManager 192.168.79.131 hadoop2 DataNode NodeManager
CentOS 7使用hostnamectl set-hostname hadoop0设置主机名,其他几台同样操作,输入后可通过hostnamectl status查看是否修改成功
[root@hadoop0 ~]# hostnamectl status
Static hostname: hadoop0
Icon name: computer-vm
Chassis: vm
Machine ID: 4eddbba909c84e159cfa474604412c3c
Boot ID: df37e835fde94d039153028c9479b68e
Virtualization: vmware
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-693.el7.x86_64
Architecture: x86-64
由于hadoop0是根节点,用于资源调度,故其需要具有所有DataNode的访问地址和权限,进入/etc/hosts文件,添加如下内容将主机名解析到对应的IP
192.168.79.129 hadoop0
192.168.79.130 hadoop1
192.168.79.131 hadoop2
SSH免密码登录
进入当前用户的根目录/home/hadoop/.ssh/,在该目录下执行ssh-keygen -t rsa生成主机公钥,过程中弹出的除了 Overwrite (y/n)? y选择y确认覆盖之外,其余全为空值,则可生成免密码登录的公钥
【注意】Ubuntu系统操作略有特殊,建议使用CentOS系统进行操作
[hadoop@hadoop0 root]$ cd /home/hadoop/.ssh/
[hadoop@hadoop0 .ssh]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
/home/hadoop/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:RjyGCGedx9xzxXG97KGgjXMIZ/pg7Q+tLU1nJoxIhm8 hadoop@hadoop0
The key's randomart image is:
+---[RSA 2048]----+
| . o. + . oo.o|
| + .oo+ o . ...|
| . o.= o . .|
| . * + . + |
| + S B . o .|
| E B.* = . |
| o +.=.= |
| ++. |
| .oo |
+----[SHA256]-----+
使用ssh-copy-id将本地主机的公钥复制到远程主机的authorized_keys文件上,此时先对本地主机hadoop0授权
[hadoop@hadoop0 .ssh]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop0
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
The authenticity of host 'hadoop0 (fe80::e99d:ad75:28e9:9276%ens33)' can't be established.
ECDSA key fingerprint is SHA256:GEEH9kBVcDuaYpJZLNsaWZA3O47+HdqIbd91fGAWcew.
ECDSA key fingerprint is MD5:cd:df:9e:8c:92:3a:9f:ae:b0:10:9b:b6:25:9c:4d:c6.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@hadoop0's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop0'"
and check to make sure that only the key(s) you wanted were added.
测试SSH免密码登录成功
[hadoop@hadoop0 /]$ ssh hadoop0
Last login: Sat Apr 21 17:18:37 2018
[hadoop@hadoop0 ~]$ exit
登出
Connection to hadoop0 closed.
对另外两台主机访问授权 hadoop1
[hadoop@hadoop0 root]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
The authenticity of host 'hadoop1 (192.168.79.130)' can't be established.
ECDSA key fingerprint is SHA256:GEEH9kBVcDuaYpJZLNsaWZA3O47+HdqIbd91fGAWcew.
ECDSA key fingerprint is MD5:cd:df:9e:8c:92:3a:9f:ae:b0:10:9b:b6:25:9c:4d:c6.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@hadoop1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop1'"
and check to make sure that only the key(s) you wanted were added.
hadoop2
[hadoop@hadoop0 root]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop2
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
The authenticity of host 'hadoop2 (192.168.79.131)' can't be established.
ECDSA key fingerprint is SHA256:GEEH9kBVcDuaYpJZLNsaWZA3O47+HdqIbd91fGAWcew.
ECDSA key fingerprint is MD5:cd:df:9e:8c:92:3a:9f:ae:b0:10:9b:b6:25:9c:4d:c6.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@hadoop2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop2'"
and check to make sure that only the key(s) you wanted were added.
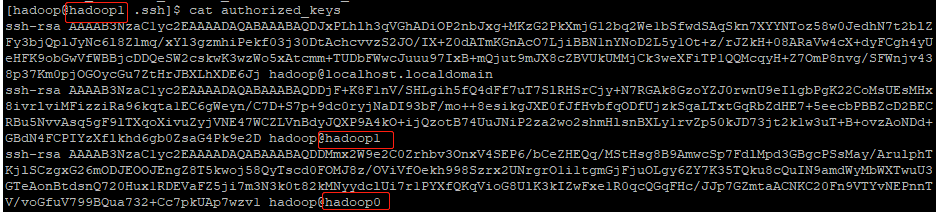
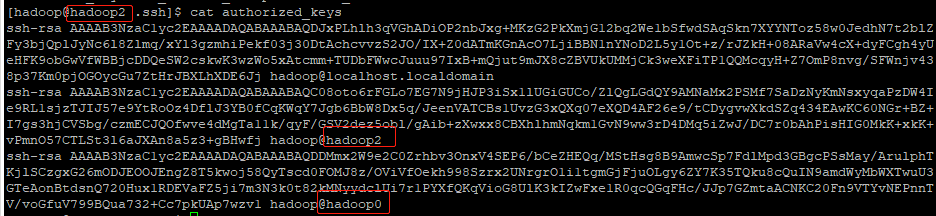
对另外两台主机做类似操作,即仅对本地主机授权,无需对hadoop0主机授权,操作后可查看authorized_keys文件内容,当前主机名即可
环境变量
三台主机均由之前的单节点主机克隆而来,故宝塔、java、hadoop环境是自带的 Java8
[hadoop@hadoop0 .ssh]$ java -version
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)
[hadoop@hadoop0 .ssh]$ javac -version
javac 1.8.0_121
hadoop
[hadoop@hadoop0 .ssh]$ cd /www/hadoop
[hadoop@hadoop0 hadoop]$
[hadoop@hadoop0 hadoop]$ ls
hadoop-2.6.0-cdh5.7.0 hadoop-2.6.0-cdh5.7.0.tar.gz testFile tmp
[hadoop@hadoop0 hadoop]$ source ~/.bash_profile
$HADOOP_HOME
[hadoop@hadoop0 hadoop]$ echo $HADOOP_HOME
/www/hadoop/hadoop-2.6.0-cdh5.7.0
hadoop配置
若之前配置过hadoop,建议将原目录删除后重新解压,主节点和从节点的目录都要删除干净,否则会导致大量问题 配置主节点core-site.xml
fs.defaultFS
hdfs://192.168.79.129:8020
配置HDFS文件存放目录和节点数hdfs-site.xml
dfs.namenode.name.dir
/www/hadoop/app/tmp/dfs/name
dfs.datanode.data.dir
/www/hadoop/app/tmp/dfs/data
配置YARN的yarn.xml,删除单节点的配置,添加如下字段
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.resourcemanager.hostname
hadoop0
配置从节点slave,默认slave为localhost
[hadoop@hadoop0 hadoop]$ cat slaves
localhost
加入host配置
[hadoop@hadoop0 hadoop]$ cat slaves
hadoop0
hadoop1
hadoop2
额外配置,启用jobhistory
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
192.168.79.129:10020
MapReduce JobHistory Server IPC host:port
mapreduce.jobhistory.webapp.address
192.168.79.129:19888
MapReduce JobHistory Server Web UI host:port
mapreduce.jobhistory.done-dir
/history/done
mapreduce.jobhistory.intermediate-done-dir
/history/done_intermediate
【注意】配置好后将单节点时的/www/hadoop/hadoop-2.6.0-cdh5.7.0/logs文件夹删除或者直接重新解压hadoop的压缩包防止出现文件夹权限导致的错误
资源分发
将主节点的所有配置分发到从节点,避免重复配置。在主节点执行如下命令即可
scp -r /www/hadoop hadoop@hadoop1:/www
scp -r /www/hadoop hadoop@hadoop2:/www

分发完成
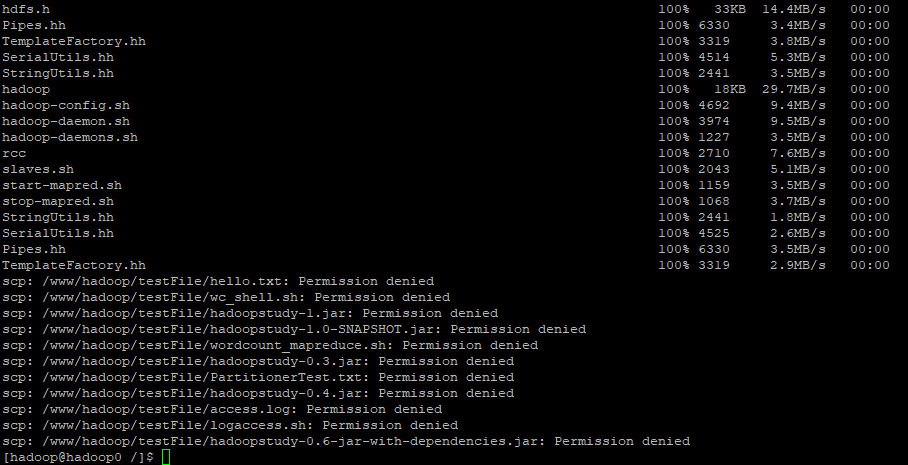
去根节点查看文件是否已经传到,分别执行source ~/.bash_profile以启用hadoop命令
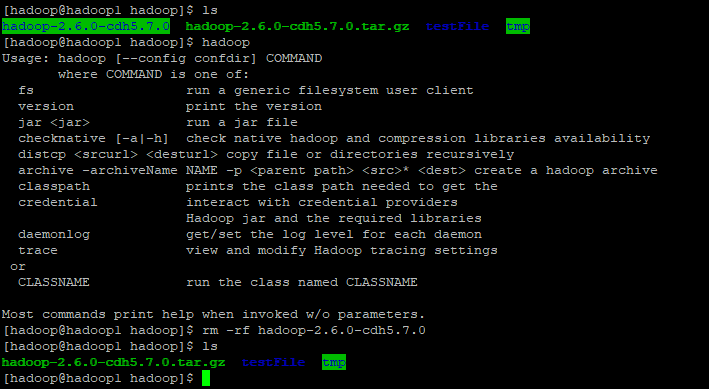
注意分发前执行一次hadoop命令是报未找到命令,说明从节点的hadoop旧根目录是删除干净的,分发完成后再次执行命令就有效了
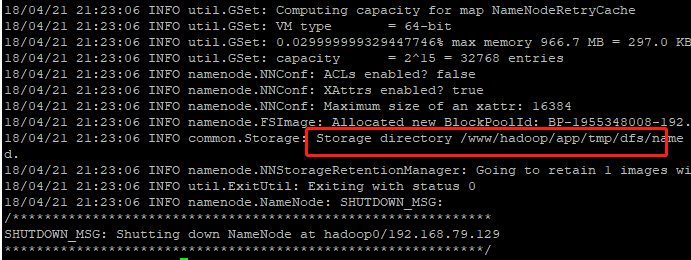
NameNode格式化
格式化只对主节点执行即可
hdfs namenode -format
格式化成功
hadoop分布式启动
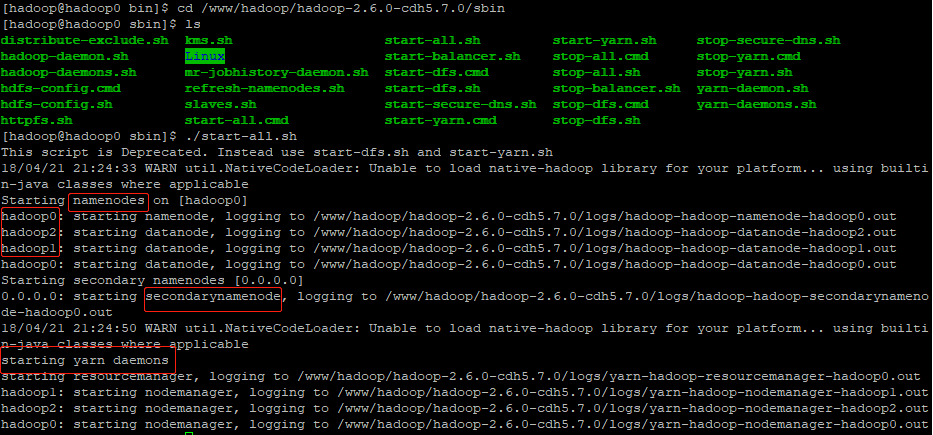
主节点启动,在/sbin目录下,执行./start-all.sh
[hadoop@hadoop0 bin]$ cd ../sbin
[hadoop@hadoop0 sbin]$ ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
18/04/21 22:16:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [hadoop0]
从节点的datanode和namenode逐一启动
hadoop0: starting namenode, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-namenode-hadoop0.out
hadoop1: starting datanode, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-datanode-hadoop1.out
hadoop0: starting datanode, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-datanode-hadoop0.out
hadoop2: starting datanode, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-datanode-hadoop2.out
Starting secondary namenodes [0.0.0.0]
主节点secondarynamenode启动
0.0.0.0: starting secondarynamenode, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-secondarynamenode-hadoop0.out
18/04/21 22:16:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
启动yarn和resourcemanager、nodemanager
starting yarn daemons
starting resourcemanager, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-resourcemanager-hadoop0.out
hadoop1: starting nodemanager, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-hadoop1.out
hadoop2: starting nodemanager, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-hadoop2.out
hadoop0: starting nodemanager, logging to /www/hadoop/hadoop-2.6.0-cdh5.7.0/logs/yarn-hadoop-nodemanager-hadoop0.out
hadoop分布式启动验证
命令行方式
使用jps查看进程,以下进程少一个都不行,若缺少,查看另一篇文章寻找解决办法hadoop分布式搭建的一些坑
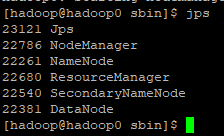
[[hadoop分布式搭建的一些坑]]
启动主节点后从节点的HDFS会自动启动,进入从节点,使用jps查看,有两个进程即成功
[hadoop@hadoop2 hadoop]$ jps
29876 Jps
29575 DataNode
29692 NodeManager
webUI方式
使用webUI确认所有进程成功启动,查看HDFS节点
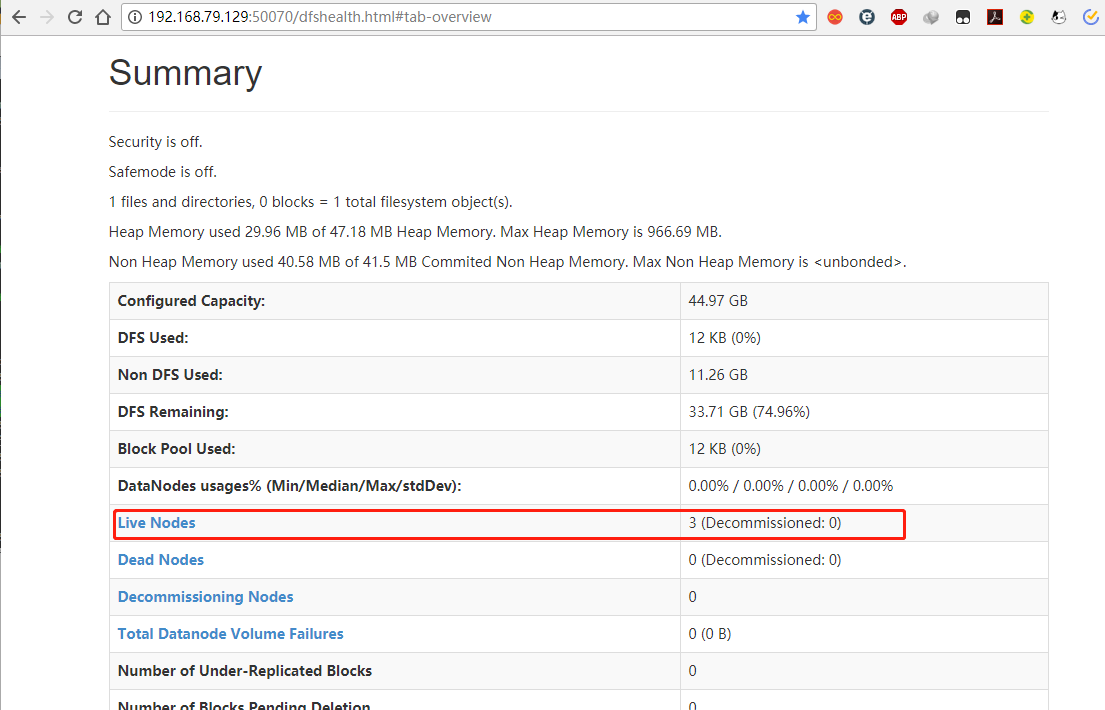
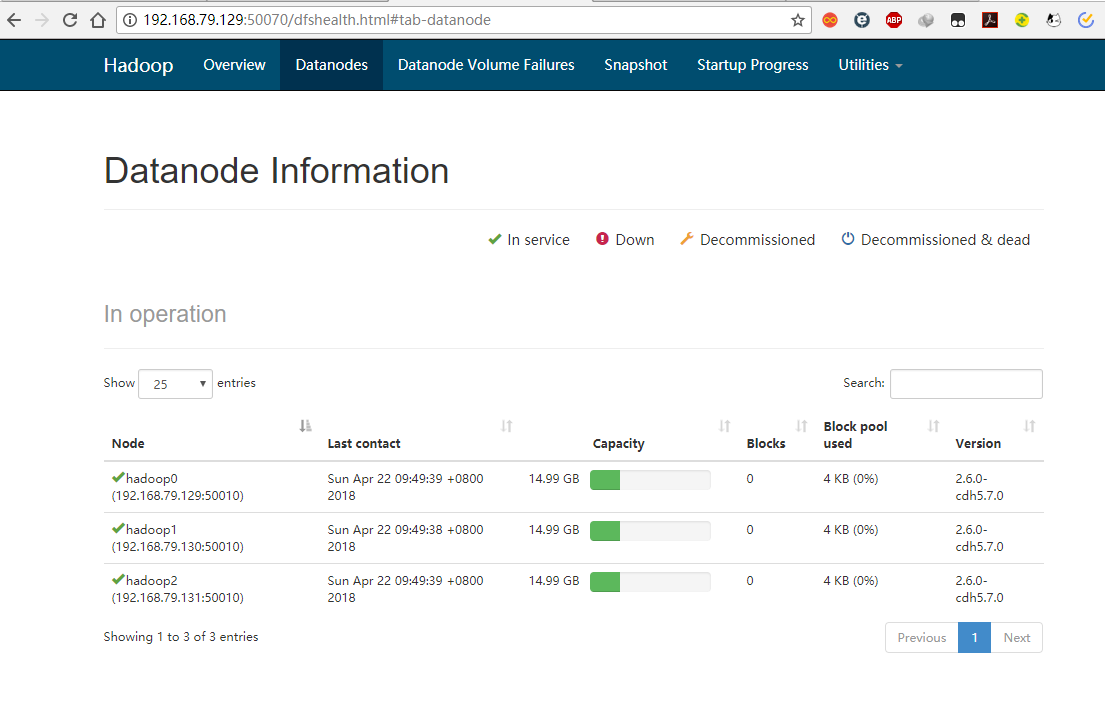
查看YARN
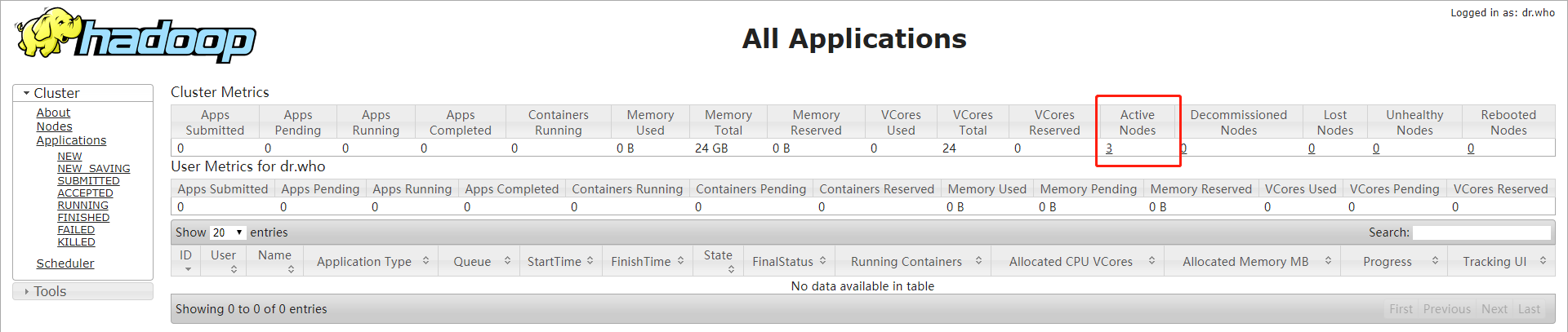
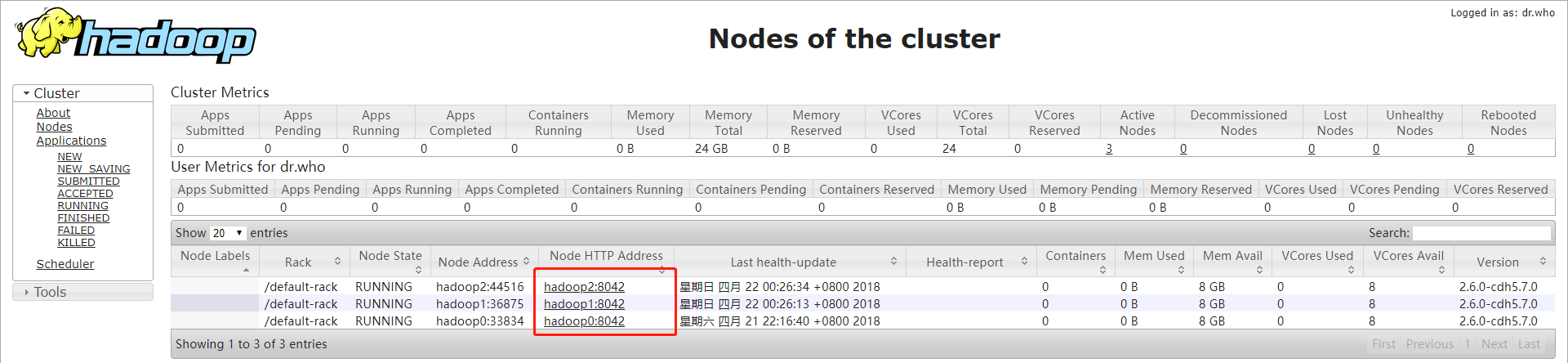
已经有三个从节点注册到YARN
分布式集群测试
分布式文件测试
上传测试文件再查看节点情况 初始节点为空
[hadoop@hadoop0 hadoop-2.6.0-cdh5.7.0]$ ls
bin cloudera examples include libexec logs README.txt share
bin-mapreduce1 etc examples-mapreduce1 lib LICENSE.txt NOTICE.txt sbin src
[hadoop@hadoop0 hadoop-2.6.0-cdh5.7.0]$ hadoop fs -ls /
18/04/21 22:33:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
新建数据目录
[hadoop@hadoop0 hadoop-2.6.0-cdh5.7.0]$ hadoop fs -mkdir /data
18/04/21 22:33:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop0 hadoop-2.6.0-cdh5.7.0]$ hadoop fs -ls /
18/04/21 22:33:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-04-21 22:33 /data
上传小文件
[hadoop@hadoop0 hadoop-2.6.0-cdh5.7.0]$ hadoop fs -put README.txt /data
18/04/21 22:34:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop0 hadoop-2.6.0-cdh5.7.0]$ hadoop fs -ls /data
18/04/21 22:34:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 3 hadoop supergroup 1366 2018-04-21 22:34 /data/README.txt
上传大文件
[hadoop@hadoop0 hadoop]$ ll
总用量 304284
drwxrwxr-x 3 hadoop hadoop 17 4月 21 22:16 app
drwxrwxrwx 15 www www 253 4月 21 22:08 hadoop-2.6.0-cdh5.7.0
-rwxrwxrwx 1 www www 311585484 3月 31 23:06 hadoop-2.6.0-cdh5.7.0.tar.gz
drwxr-xr-x 2 www www 301 4月 11 06:31 testFile
[hadoop@hadoop0 hadoop]$ hadoop fs -put hadoop-2.6.0-cdh5.7.0.tar.gz /data
18/04/21 22:35:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop0 hadoop]$ hadoop fs -ls /data
18/04/21 22:36:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 3 hadoop supergroup 1366 2018-04-21 22:34 /data/README.txt
-rw-r--r-- 3 hadoop supergroup 311585484 2018-04-21 22:36 /data/hadoop-2.6.0-cdh5.7.0.tar.gz
通过webUI查看文件情况
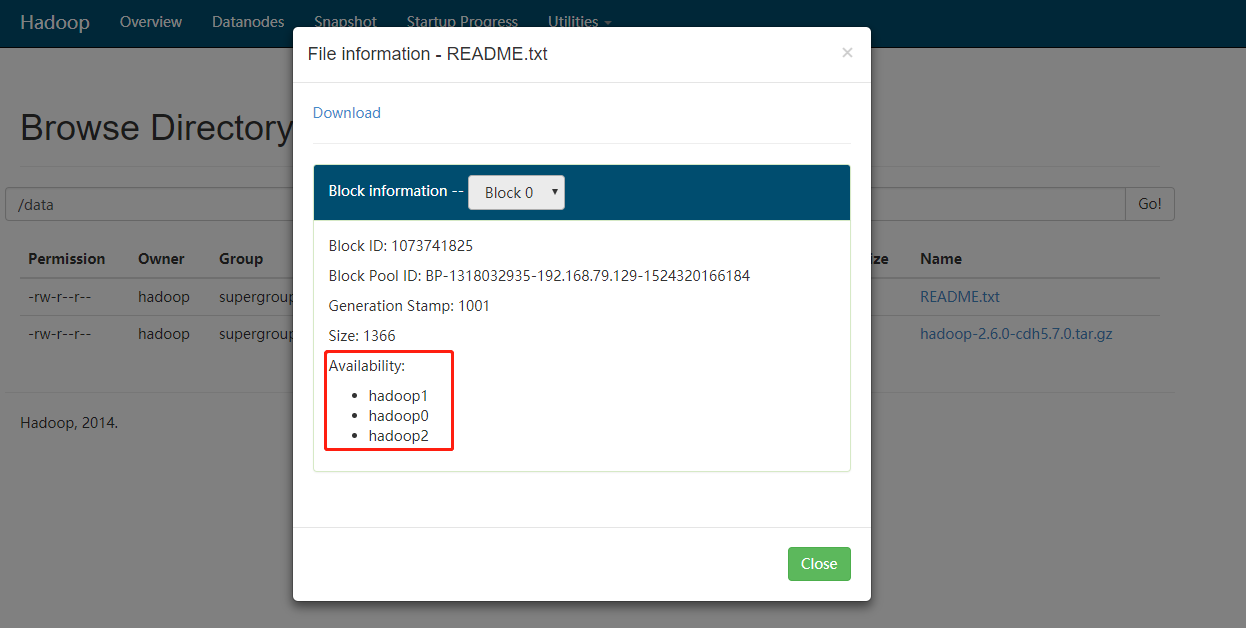
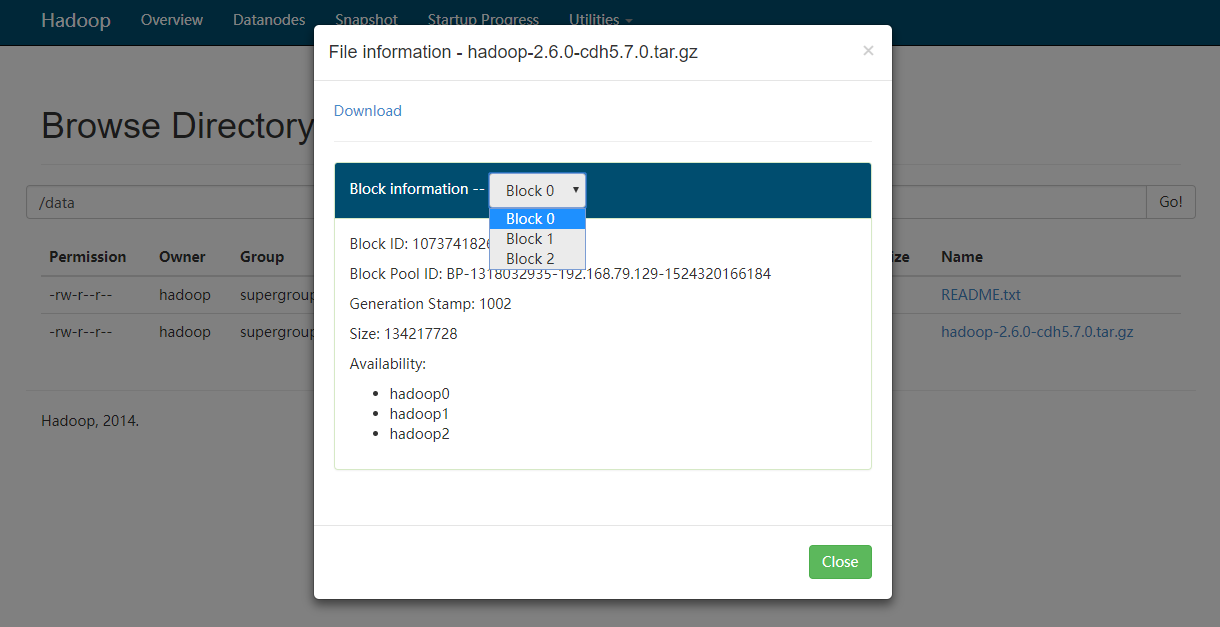
分布式MapReduce测试
测试MapReduce,进入/www/hadoop/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce目录,执行pi运算hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 2 3
【注意】由于此处是虚拟机,不建议将后面的精度设置过大,否则会报IO错误
进入YARN的web界面查看

运行成功
分布式日志离线处理测试
上传日志数据 [hadoop@hadoop0 testFile]$ hadoop fs -put access.log /data 18/04/21 23:42:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 执行
hadoop jar hadoopstudy-0.6-jar-with-dependencies.jar com.fjy.hadoop.hadoop.project.LogApp /data/access.log /logaccess/out
Web查看工作详情

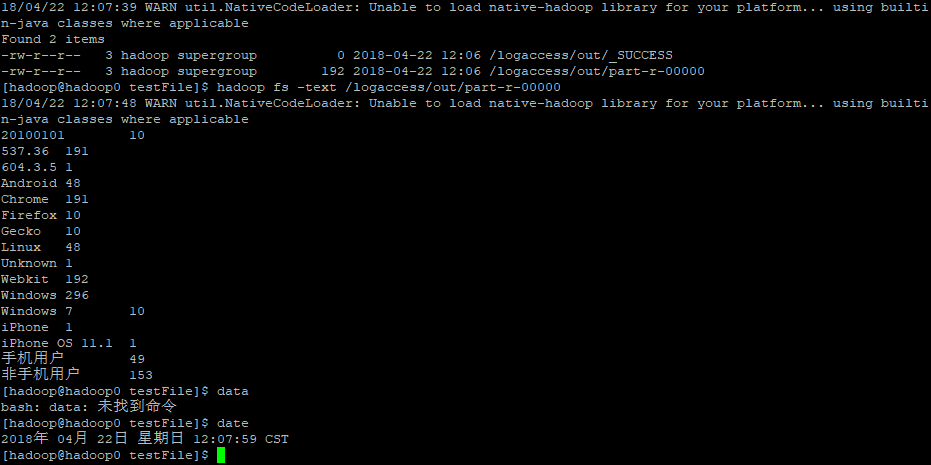
查看结果
题外话
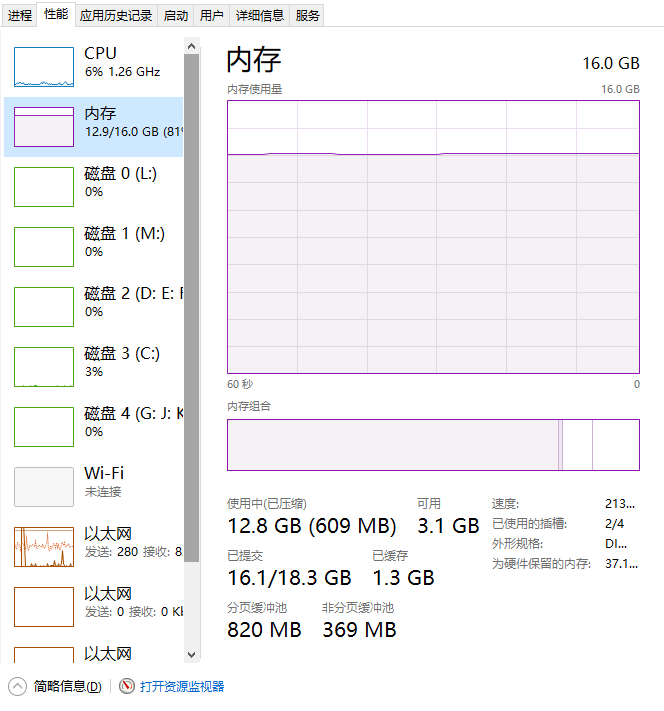
其实同时运行三台虚拟机是很吃配置的,特别是内存,对于hadoop来说内存太小很多都会报异常,因此本次的测试机器配置还可以的,三台虚拟机均运行在480G SATA3的固态上
CPU:7700 4core 8thread
RAM:16G DDR4 Dual Channal
SSD:128+480 nvme+sata3
HDD:9T sata3
Eth:1000M I219V
但在实际运行中依然顶着内存瓶颈,多次使用了系统盘的交换分区