DataNode没启动
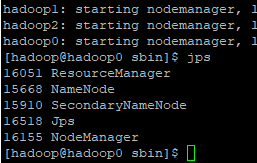
这种情况多出现于该机器之前配置过hadoop,没清理干净的情况,即仍有文件目录,导致新hadoop的clusterID与旧的不一致,导致HDFS无法启动,报JavaIO异常
2018-04-22 00:21:15,868 WARN org.apache.hadoop.hdfs.server.common.Storage: java.io.IOException: Incompatible clusterIDs in /www/hadoop/app/tmp/dfs/data: namenode clusterID = CID-6c7766c6-b260-42b6-8c03-07dda802c0cf; datanode clusterID = CID-a53df7ad-e593-4a29-ad15-a93486c54776
2018-04-22 00:21:15,868 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool (Datanode Uuid unassigned) service to hadoop0/192.168.79.129:8020. Exiting.
java.io.IOException: All specified directories are failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:478)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1394)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1355)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:228)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:829)
at java.lang.Thread.run(Thread.java:745)
2018-04-22 00:21:15,869 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Ending block pool service for: Block pool (Datanode Uuid unassigned) service to hadoop0/192.168.79.129:8020
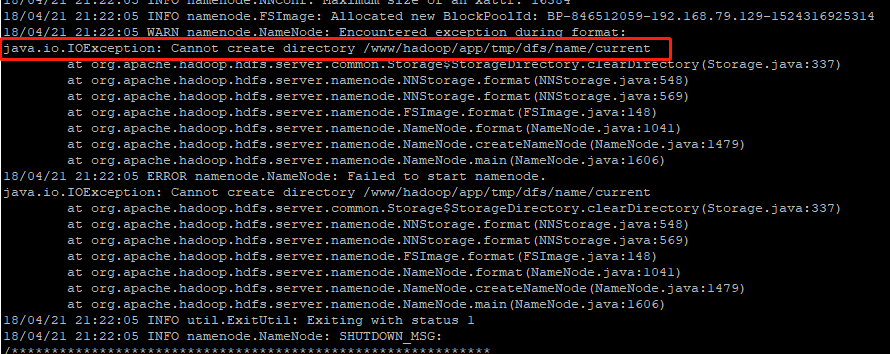
解决方案
清理所有节点的旧文件存储目录,重新再根节点格式化存储空间
rm -rf app/
hdfs namenode -format
重新启动HDFS
[hadoop@hadoop0 bin]$ cd ../sbin
[hadoop@hadoop0 sbin]$ ./start-all.sh
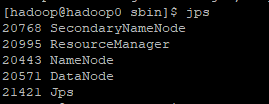
查看进程,DataNode已启动
[hadoop@hadoop0 sbin]$ jps
37618 DataNode
37783 SecondaryNameNode
37932 ResourceManager
37485 NameNode
38045 NodeManager
38365 Jps
NodeManager没启动/启动后进程消失
该情况由于yarn-site.xml文件配置有误,导致从节点找不到主节点,报JavaNet异常
org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.net.BindException: Problem binding to [hadoop0:0] java.net.BindException: 无法指定被请求的地址; For more details see: http://wiki.apache.org/hadoop/BindException
at org.apache.hadoop.yarn.factories.impl.pb.RpcServerFactoryPBImpl.getServer(RpcServerFactoryPBImpl.java:139)
at org.apache.hadoop.yarn.ipc.HadoopYarnProtoRPC.getServer(HadoopYarnProtoRPC.java:65)
at org.apache.hadoop.yarn.ipc.YarnRPC.getServer(YarnRPC.java:54)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.ContainerManagerImpl.serviceStart(ContainerManagerImpl.java:406)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:193)
at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:120)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.serviceStart(NodeManager.java:266)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:193)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.initAndStartNodeManager(NodeManager.java:475)
at org.apache.hadoop.yarn.server.nodemanager.NodeManager.main(NodeManager.java:521)
解决方案
重新配置yarn-site.xml,确保其有下面这一段,并且使用SSH 主机名能够访问该节点
yarn.resourcemanager.hostname
hadoop0
YARN运算IO错误
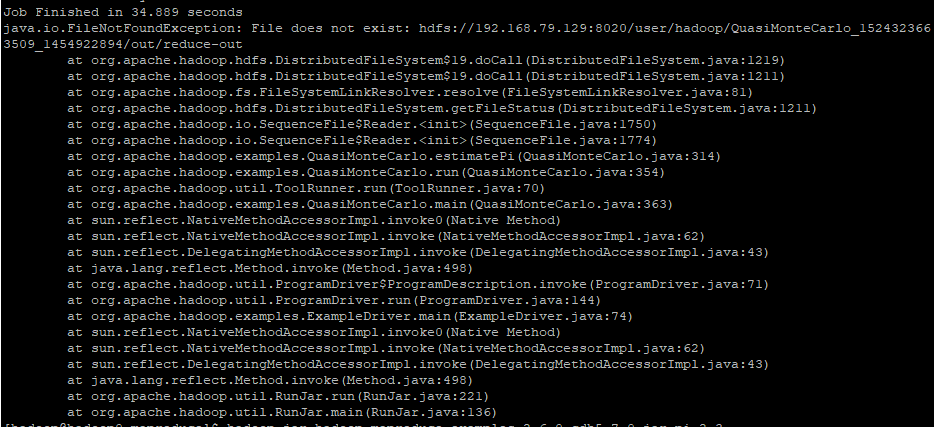
该错误由于机器内存过小,却执行复杂的运算,导致内存不足,报JavaIO异常,例如在2G内存的机器上执行 hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 4 5运算
Job Finished in 34.889 seconds
java.io.FileNotFoundException: File does not exist: hdfs://192.168.79.129:8020/user/hadoop/QuasiMonteCarlo_1524323663509_1454922894/out/reduce-out
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1219)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:1211)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1211)
at org.apache.hadoop.io.SequenceFile$Reader.(SequenceFile.java:1750)
at org.apache.hadoop.io.SequenceFile$Reader.(SequenceFile.java:1774)
at org.apache.hadoop.examples.QuasiMonteCarlo.estimatePi(QuasiMonteCarlo.java:314)
at org.apache.hadoop.examples.QuasiMonteCarlo.run(QuasiMonteCarlo.java:354)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.examples.QuasiMonteCarlo.main(QuasiMonteCarlo.java:363)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71)
at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
YARN也显示工作失败

解决方案
调整虚拟内存,或者减小运算精度,例如设置精度为hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 2 3则一般不会有问题
机器时间不同步
该问题出现在MapReduce测试时,若主从节点机器时间不一致则会报同步错误
18/04/21 23:55:20 INFO mapreduce.Job: Task Id : attempt_1524320196806_0003_m_000000_2, Status : FAILED
Container launch failed for container_1524320196806_0003_01_000004 : org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container.
This token is expired. current time is 1524333912535 found 1524326717165
Note: System times on machines may be out of sync. Check system time and time zones.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:168)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:159)
at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:379)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
解决方案
首先检查各节点的时间 主节点
[hadoop@hadoop0 testFile]$ timedatectl status
Local time: 六 2018-04-21 23:57:21 CST
Universal time: 六 2018-04-21 15:57:21 UTC
RTC time: 六 2018-04-21 15:44:44
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: yes
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
从节点1
[hadoop@hadoop1 hadoop]$ timedatectl status
Local time: 日 2018-04-22 02:06:49 CST
Universal time: 六 2018-04-21 18:06:49 UTC
RTC time: 六 2018-04-21 17:54:14
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: yes
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
从节点2
[hadoop@hadoop2 hadoop]$ timedatectl status
Local time: 日 2018-04-22 02:07:00 CST
Universal time: 六 2018-04-21 18:07:00 UTC
RTC time: 日 2018-04-22 04:00:48
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: yes
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
三个节点显然时间不一致,使用ntpdate工具同步各机器时间
[root@hadoop2 hadoop]# yum -y install ntp ntpdate
已加载插件:fastestmirror
base | 3.6 kB 00:00:00
epel/x86_64/metalink | 7.7 kB 00:00:00
epel | 4.7 kB 00:00:00
extras | 3.4 kB 00:00:00
updates | 3.4 kB 00:00:00
(1/4): epel/x86_64/updateinfo | 916 kB 00:00:01
(2/4): extras/7/x86_64/primary_db | 185 kB 00:00:01
(3/4): epel/x86_64/primary_db | 6.3 MB 00:00:01
(4/4): updates/7/x86_64/primary_db | 6.9 MB 00:00:03
Determining fastest mirrors
* base: centos.ustc.edu.cn
* epel: mirror01.idc.hinet.net
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
软件包 ntp-4.2.6p5-25.el7.centos.2.x86_64 已安装并且是最新版本
软件包 ntpdate-4.2.6p5-25.el7.centos.2.x86_64 已安装并且是最新版本
无须任何处理
[root@hadoop2 hadoop]# ntpdate cn.pool.ntp.org
22 Apr 12:02:55 ntpdate[36396]: step time server 108.59.2.24 offset 35618.521668 sec
将时间偏差写入机器时间
[root@hadoop2 hadoop]# hwclock --systohc
[root@hadoop2 hadoop]# date
2018年 04月 22日 星期日 12:03:33 CST
问题解决
