Loading...
请输入密码访问
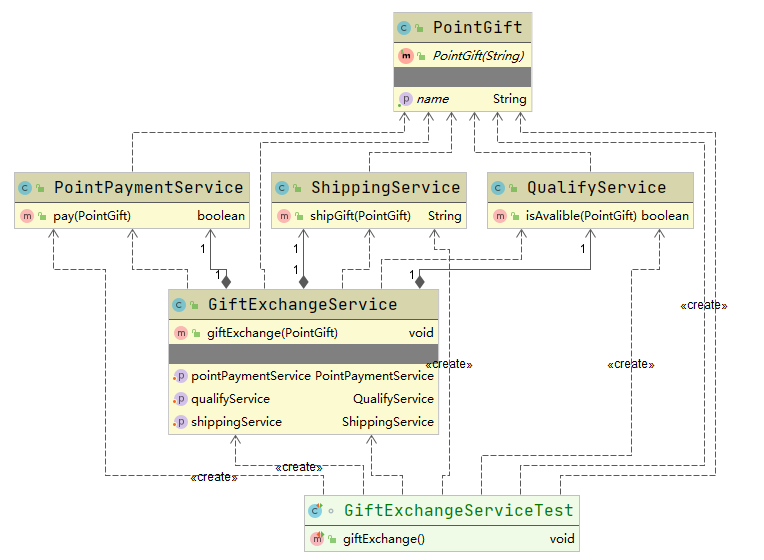
外观模式 介绍 又叫门面模式,提供了一个统一的接口,用来访问子系统中的一群接口 外观模式定义了一个高层接...
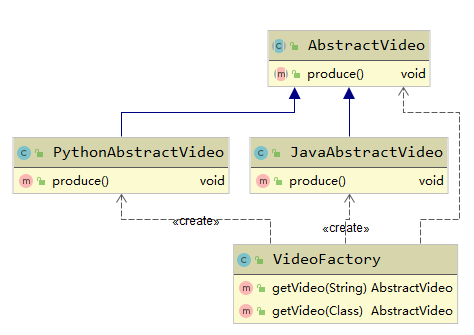
简单工厂 介绍 定义由一个工厂对象决定创建出哪一种产品类的实例 类型:创建型,但不属于GOF23种设计模...
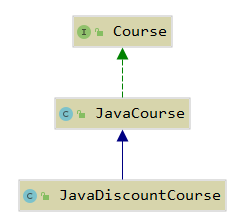
开闭原则 介绍 定义:一个软件实体如类、模块和函数应该对扩展开放,对修改关闭 用抽象构建框架,用实现扩展...
一、介绍 通用导入方法:数据量大应当使用load data方式导入,而不是使用source sql文件的...